|
|
|
|
|
FCS 南京大学俞扬等:基于因果世界模型的离线强化学习算法 |
|
|
论文标题:Offline model-based reinforcement learning with causal structured world models
期刊:Frontiers of Computer Science
作者:Zhengmao ZHU, Honglong TIAN, Xionghui CHEN, Kun ZHANG2, Yang YU
发表时间:24 Jul 2024
DOI: 10.1007/s11704-024-3946-y
微信链接:点击此处阅读微信文章

引用格式:
Zhengmao ZHU, Honglong TIAN, Xionghui CHEN, Kun ZHANG, Yang YU. Offline model-based reinforcement learning with causal structured world models. Front. Comput. Sci., 2025, 19(4): 194347
阅读原文:

研究内容
本文在离线强化学习场景下,从理论上分析了因果世界模型如何影响策略性能,并研究了如何在离线场景下准确地捕捉因果关系并构建因果世界模型。文章分析发现,将因果结构纳入环境模型的学习可以改进泛化误差界限,从而证明了因果世界模型对策略性能的正面影响。同时,文章还开发了一种离线强化学习场景下的高效因果发现方法,通过利用强化学习的数据特性降低了独立性假设检验的次数,从而提高了因果发现效率,同时还维持了因果发现的准确性。
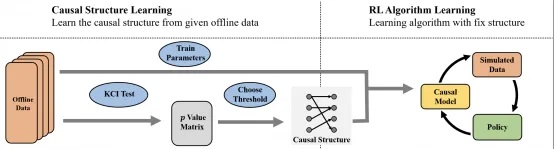
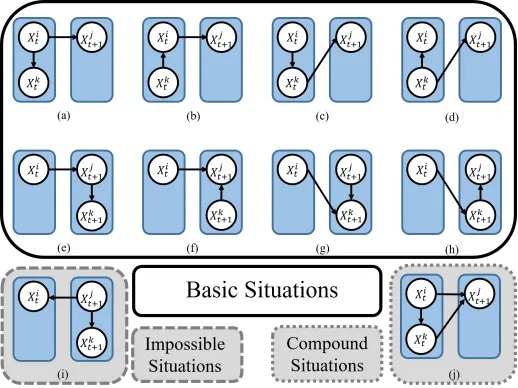
核心步骤
1、我们将三元组所有可能的因果关系列出,并删去其中不可能在强化学习场景中出现的结构和无需讨论的复合结构。
2、在剩余的可能结构中,我们发现可以用非常简洁的原则进行独立性假设检验,即:把当前时刻t的变量放入条件集,把未来时刻t+1的变量不放入条件集。
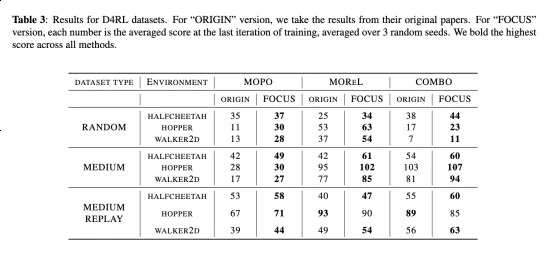
实验结果
结果表明,所提出的基于因果世界模型的离线强化学习算法,在多个实验环境中,可以比基于非因果模型的离线强化学习算法取得显著的优势。
中国学术前沿期刊网
http://journal.hep.com.cn
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






