
导读
随着人工智能规模的不断扩大,传统电子芯片在算力、能耗与带宽方面逐渐遭遇“摩尔定律失效”的瓶颈。光子芯片因其并行性与高速性,成为后摩尔时代突破算力极限的重要方向。自由空间衍射神经网络,凭借三维架构,具备高通量与高并行度优势。然而,其系统一直受限于模块体积庞大与信息编码速率较低,严重制约了计算频率和小型化进程。
近日,上海理工大学智能科技学院顾敏院士团队在 eLight期刊发表最新成果,提出并演示了一种垂直集成的光学图像处理器(OGPU)。该架构引入可寻址垂直腔面发射激光器(VCSEL) 阵列作为光源与信息编码器件,并通过多模块垂直堆叠实现系统级集成,成功实现每秒 2500 万帧的超高速图像识别。该成果为不同于硅基芯片的全新集成路径提供了可能,展现出超大规模计算与超高通量的广阔前景。
论文以 “High-throughput optical neuromorphic graphic processing at millions of images per second”为题发表在eLight(影响因子32.1,入选两期卓越计划)。董毅博博士为第一作者,顾敏院士、栾海涛副研究员、张启明教授为通讯作者。
人工智能和高性能计算的迅猛发展,对算力和能效提出了前所未有的挑战。电子芯片虽不断迭代,但在能效和规模扩展方面已逐渐逼近极限。相比之下,光计算因其高速、并行、低功耗的特性,被认为是突破瓶颈的关键方向。近年来,二维硅光芯片在片上干涉网络计算方面已经取得显著进展,并催生了产业化探索。然而,二维架构受限于平面布局,其在计算规模和通量提升方面仍存在明显瓶颈。
与二维架构相比,衍射神经网络(DNN)为代表的自由空间光计算能够通过层层光学衍射实现大规模并行运算,具有更接近人脑的三维结构和计算模式。自由空间光子计算具备“单发式(single-shot)”的信息处理能力,可以直接处理二维图像数据、支持超大规模神经元数量,是高通光计算的重要发展方向。但长期以来,三维光计算系统受制于器件分散、体积庞大、缺乏成熟的芯片架构和集成工艺,始终难以实现真正的芯片化与小型化。
本研究提出了垂直集成架构的光学图像处理芯片(图1a),能够执行图像识别与处理任务(图1b)。其核心由可寻址VCSEL阵列、相互非相干衍射神经网络(MI-DNN)芯片和探测器芯片组成(图1c)。凭借VCSEL阵列的二维排布、高速调制(GHz)、平面出光、可编程性以及芯片级尺寸,该架构实现了光源、驱动、计算和探测模块的全集成,首次将自由空间光计算系统压缩至可手持规模(图1d),为三维光计算集成化难题提供了全新解决思路。
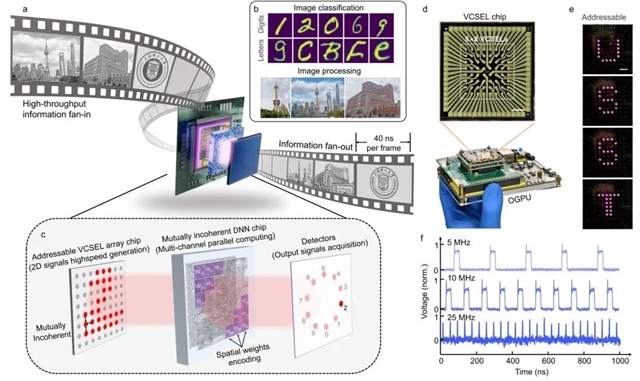
图1: OGPU 架构及性能示意a. OGPU 概念示意图,每帧图像的处理时间为 40 ns。b. OGPU 执行的任务演示,包括图像分类及图像处理(边缘提取和降噪)。c. 垂直堆叠架构概览,包括用于生成二维信号的可寻址相互非相干 VCSEL 阵列、多通道处理的 MI-DNN,以及用于输出信号采集的探测器。d. OGPU 与 VCSEL 阵列的光学图像。比例尺:200 μm。e. VCSEL 阵列可寻址性的演示,显示字母 “U”、“S”、“S” 和 “T”。比例尺:200 μm。f. VCSEL 阵列产生的脉冲光信号,在 1000 ns 时间窗口内以不同频率工作
该系统无需任何透镜元件,突破了传统自由空间的体积限制,在仅7毫米光传播距离内即可完成全光推理。VCSEL阵列可直接编码图像信息(图1e),结合衍射神经网络的并行处理,实现了“单发式”图像推理:VCSEL显示图像的同时,系统已在光速下完成运算。这一特性与VCSEL的高速特性相结合,使系统达到每秒2500万帧的处理速度(图1f)。
VCSEL阵列具有区别于传统激光源的独特特性:阵列中每个VCSEL单元发射相干光,但单元之间彼此非相干。针对这一特性,团队通过光场建模与多通道并行训练,构建了相互非相干的衍射神经网络训练模型。在该模型下,MI-DNN的线性运算机制不同于以往的相干DNN架构,并展现出相干光计算与非相干光计算的协同优势,不仅具备更高的鲁棒性,还实现了更高的衍射效率。
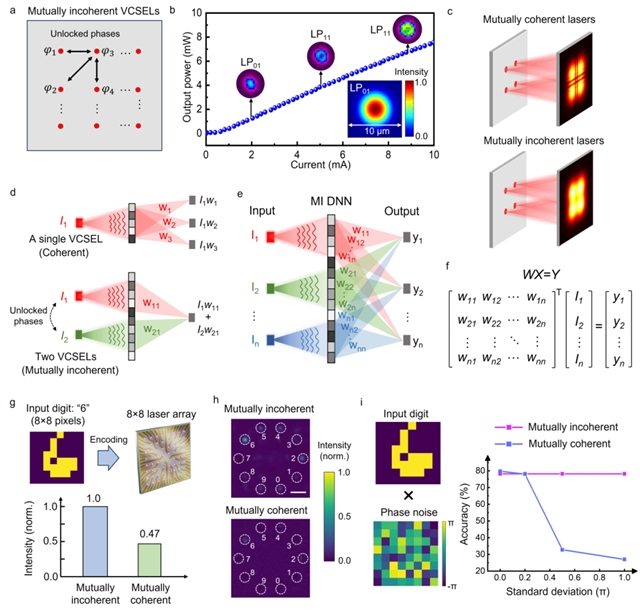
图2:OGPU 原理示意。a. VCSEL 间未锁定的相位导致阵列内相互非相干。b. VCSEL 的输出功率–电流特性曲线,以及不同电流下模式分布。c. 2×2 VCSEL 阵列远场光斑模拟,对比相互非相干与相干条件。d. MI-DNN 执行光学乘法与加法运算的原理。乘法运算利用 VCSEL 的单元相干特性,加法运算则利用 VCSEL 间的相互非相干特性。e. MI-DNN 实现光学向量–矩阵乘法的原理。f. MI-DNN 对应的向量–矩阵乘法运算示意。g. DNN 对训练集图像正确识别时输出层目标检测区域的平均强度,对比相互非相干与相干条件。h. 输入图像为“6”时,在相互非相干与相干条件下的输出示例。比例尺:200 μm。i. 输入图像叠加正态分布随机相位噪声时,DNN 在不同相位噪声标准差下的分类准确率,对比相互非相干与相干条件
在实验中,团队基于该OGPU完成了光学推理任务,对1000张图片的推理耗时仅为40微秒。在不同类型的任务中(如数字识别和字母识别),系统最高实现了98.6%的准确率。同时,实验结果表明,该系统具备26.02%的衍射效率,能够在极低光源条件下运行(每帧图像的光能量仅为3.52 aJ/μm²)。
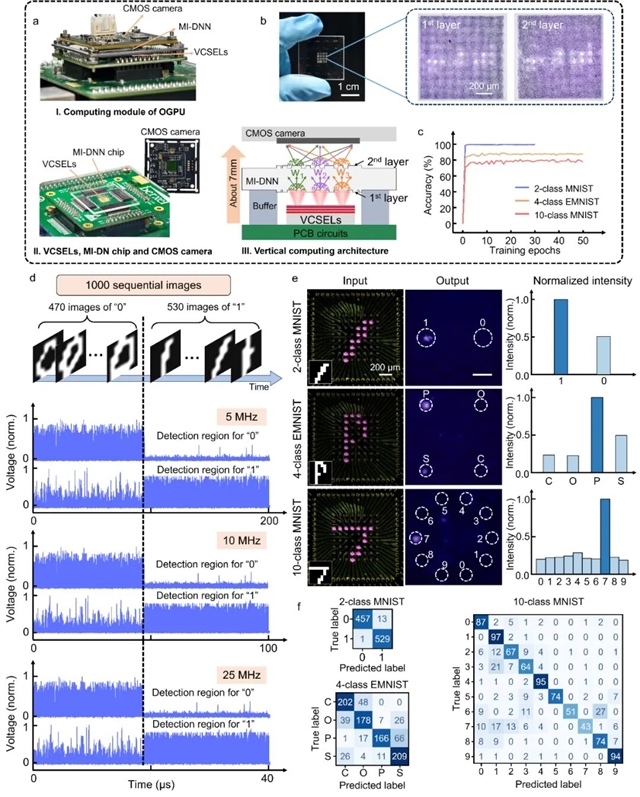
图3:使用 OGPU 的高通量图像分类。a. 计算模块的数字图像及架构。I. 计算模块实物照片。II. 放大视图显示 MI-DNN 芯片与 VCSEL 阵列及 CMOS 相机的集成情况。III. OGPU 垂直自由空间计算架构示意图,其中输入层到输出层的光传播距离仅为 7 mm。b. MI-DNN 芯片照片,以及用于二分类 MNIST 的两个衍射层光学显微镜图。c. MI-DNN 在不同任务下的训练准确率随训练次数变化曲线。d. 二分类 MNIST 数据集的高速分类结果。VCSEL 显示 1000 张 64×64 手写数字图像,前 470 张标记为 “0”,后 530 张标记为 “1”,在不同工作频率下输出。曲线显示对应“0”和“1”的两个检测区域中,高速光探测器随时间检测到的信号强度变化。e. OGPU 成功分类输入 “1”、“P” 和 “7”,目标检测区域显示最强光强。f. OGPU 对二分类 MNIST、四分类 EMNIST 和十分类 MNIST 数据集的混淆矩阵
除图像识别外,OGPU还能够胜任图像处理任务。得益于分布式MI-DNN的设计,系统可并行执行四种不同的边缘提取操作,从而实现对图像多类型边缘的检测。更为重要的是,依托VCSEL之间的相互非相干特性,MI-DNN能够实现卷积核运算功能,大幅拓展了潜在应用范围。在文中,作者进一步展示了基于高斯卷积核的图像降噪处理功能。
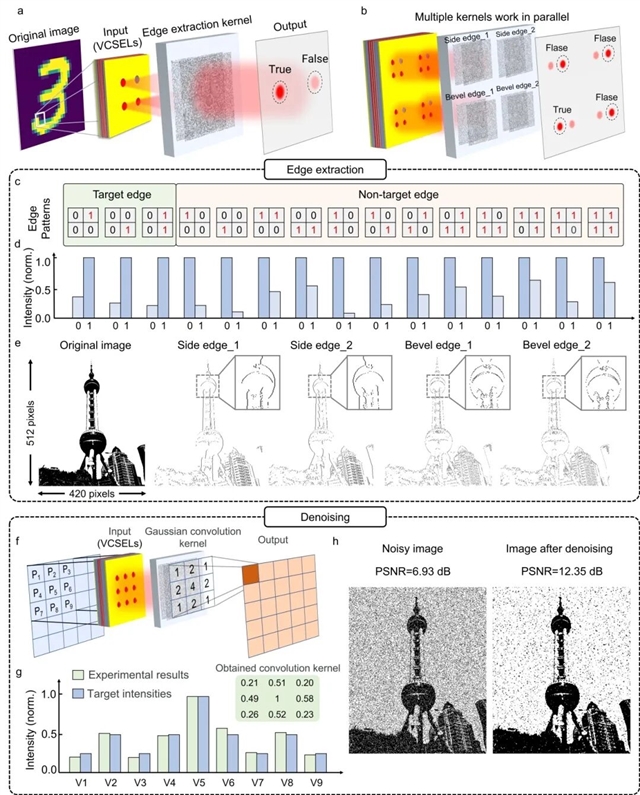
图4:使用 OGPU 的高通量图像处理。a. OGPU 工作原理示意图。滤波器从原始图像中提取 2×2 像素区域,步长为 1 像素,将数据编码到 2×2 VCSEL 单元中。随后,MI-DNN 作为边缘提取卷积核,检测目标边缘模式。当检测到目标边缘时,识别结果为 “True”,否则为 “False”。b. OGPU 支持多个边缘提取卷积核并行工作。c.其中一种边缘提取 MI-DNN 识别的目标边缘与非目标边缘样式。d. 对应 (c) 中不同边缘识别的实验结果。e. 对东方明珠塔图像进行边缘提取的结果,由四个不同目标边缘模式的 MI-DNN 处理。为便于观察,图像灰度已反转。f. 3×3 像素高斯卷积的数学运算流程及 OGPU 上 MI-DNN 对应实现,用于高斯滤波降噪。g. OGPU 中用于高斯滤波的 3×3 VCSEL 阵列各通道输出强度。h. OGPU 的图像降噪结果。噪声图像峰值信噪比(PSNR)为 6.93 dB,处理并二值化后,降噪图像的 PSNR 提升至 12.35 dB
总结与展望
该研究提出的垂直集成光子芯片,为三维光计算提供了一条不同于硅基平面芯片的新路径,具备大规模扩展与高性能应用的巨大潜力。凭借VCSEL阵列的平面特性,可望实现上万单元级别的超大规模光源阵列,从而支撑更大规模的分布式光计算。同时,需要说明的是,目前实现的每秒2500万帧速度远未触及该芯片架构的物理极限,随着驱动电路优化,有望达到上亿帧/秒的处理水平,以满足人工智能时代海量数据处理需求。其具备卷积运算功能,也为在更多人工智能模型中发挥作用奠定了基础。未来,该技术有望在智能驾驶、智慧医疗、机器视觉及大语言模型加速等领域展现重要价值。(来源:中国光学微信公众号)
相关论文信息:https://doi.org/10.1186/s43593-025-00106-9
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






