|
|
|
|
|
清华大学邱彤教授团队:催化裂化过程的智能建模与优化|MDPI Processes |
|
|
论文标题:Decarbonizing the Industry Sector: Current Status and Future Opportunities of Energy-Aware Production Scheduling
论文链接:https://www.mdpi.com/2227-9717/12/11/2474
期刊名:Processes
期刊主页: https://www.mdpi.com/journal/processes
研究背景
催化裂化(Fluid Catalytic Cracking)是炼油厂中最重要的转化工艺之一,广泛用于将原油中高沸点、高分子量的烃组分转化为更有价值的产品,如汽油、柴油。先进的建模和优化技术对提高催化裂化过程的运行效率和经济性能至关重要。近年来,随着深度学习的发展,数据驱动模型在催化裂化建模方面取得了重大进展。然而,由于黑箱性质和外推困难,这类模型难以直接应用于实时优化。来自清华大学化学工程系的邱彤教授及其团队在Processes期刊发表了文章,通过构建精确的代理模型,将数据与机理知识相结合,并将该模型嵌入到优化过程中,开发了一个用于催化裂化过程混合建模和优化的集成框架,实现了收率优化。
研究过程与结果
该研究提出的集成建模和优化框架由三个关键模块组成:混合数据收集模块、多任务学习预测模块和基于代理模型的优化模块。首先,收集工厂及基于Petro-SIM模拟程序的数据。接下来,在这个混合数据集上训练一个多任务学习模型来预测产品收率分布,多任务学习模型包括参数共享层和预测特定层,其中参数共享层(主干网络)从工厂数据和模拟数据中提取共同特征,预测特定层(头网络)分别对两类数据作出准确预测。最后,将训练好的模型作为代理纳入优化框架,对产品收益进行优化。
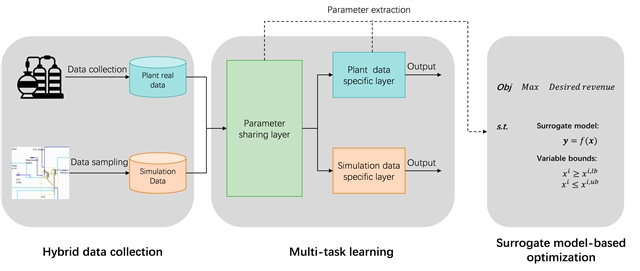
混合建模与优化框架方案
训练完成后,多任务学习模型对工厂数据集产品收率的预测误差为0.98%至4.84%,对模拟数据集预测误差范围为0.09%至0.47%,表明多任务学习模型在工厂和模拟数据集预测任务上均具有良好精度表现。从数据集中抽取一批300个点,运行建立的催化裂化优化模型。结果显示优化后,液化天然气、汽油、柴油收率分布的概率密度曲线峰值向更高的产率方向移动,表明优化装置提高了这些期望产品的产率。其中,液化天然气收率从16.97 wt%提高到17.07 wt%,汽油收率从37.06 wt%提高到38.64 wt%,柴油收率从26.36 wt%提高到27.41 wt%。最终,这三种产品的收入从每小时2,413,730元增加到2,502,356元,增长3.7%。说明该优化模型能通过调整操作变量来提高经济性能。
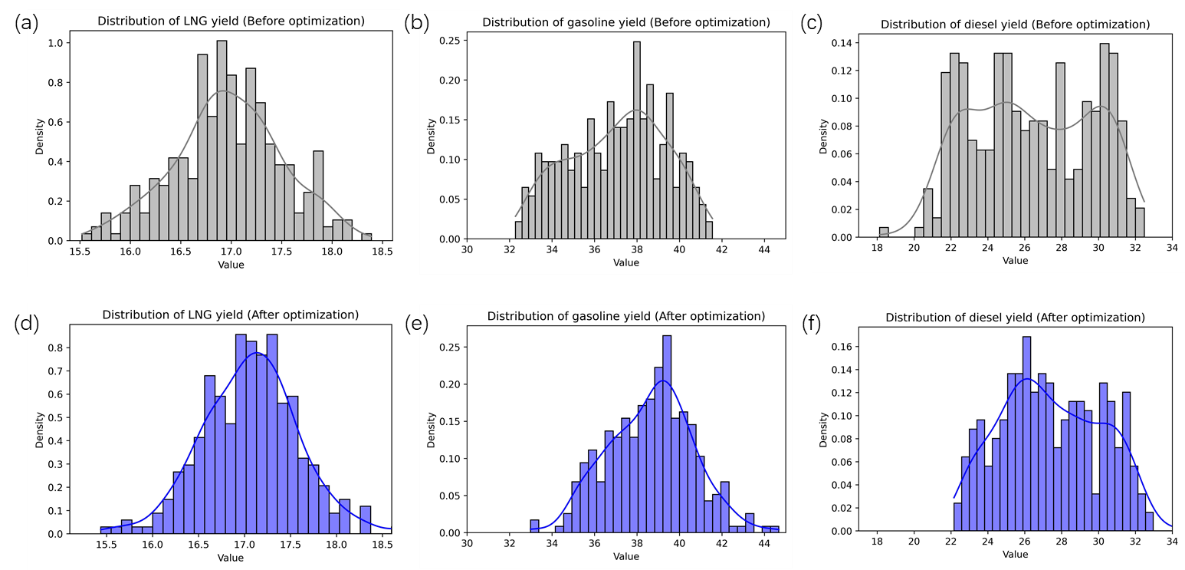
优化前后液化天然气、汽油、柴油的产品分布
研究总结
本研究提出一个将机理和数据驱动建模与优化相结合的集成框架,解决了催化裂化过程在工业环境中的操作优化问题。新颖之处包括:
•将机理模型数据与实际工厂数据相结合,提出了多源数据收集、建模和优化的统一框架;
•构建多任务学习预测模型,平衡不同数据集中包含的模式,提高预测精度和泛化能力;
•制定了嵌入数据驱动替代模型的非线性规划优化模型,提高了催化裂化过程中的产品收益。
结果表明该框架在提高工业催化裂化装置的经济效益方面有巨大潜力。
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






