|
|
|
|
|
FDE 论文解读 | K-12教育中大规模基础模型的当前趋势和未来前景 |
|
|
论文标题:Current Trends and Future Prospects of Large-Scale Foundation Model in K-12 Education
期刊:Frontiers of Digital Education
作者:Qiannan Zhu, Mei Wang, Ting Zhang, Hua Huang
发表时间:25 Jun 2025
DOI: 10.1007/s44366-025-0059-6
微信链接:点击此处阅读微信文章

在人工智能飞速发展的当下,生成式AI技术如ChatGPT、ChatGLM等掀起新一波技术革命浪潮。传统教育模式长期存在“一刀切”的弊端,新冠疫情又加速了教育数字化转型。在此背景下,大模型凭借处理海量文本数据的优势,吸引众多研究者与企业探索其在教育领域尤其K-12教育中的应用。
研究论文
北京师范大学黄华教授团队在Frontiers of Digital Education(《数字教育前沿(英文)》)期刊上发表了一篇题为Current Trends and Future Prospects of Large-Scale Foundation Model in K-12 Education的文章,系统探讨了大规模基础模型(LFMs)在K-12教育中的应用现状、技术路径、实践场景、现存挑战及未来发展方向,旨在为智能教育技术与教学实践的深度融合提供全面的技术分析与策略建议。
LFMs以Transformer架构为核心,经大规模数据训练后获得强大的语言理解与生成能力。如GPT-4在法律考试中得分超人类考生,MathGPT可解析数学公式图像。教育领域涌现出专用模型:iFLYTEK Spark支持多模态交互,EduChat融入苏格拉底教学法,TAL MathGPT能处理复杂数学问题。多模态模型(如MiniGPT-4、Qwen-vl)尝试连接图文信息,但对教学图表的理解仍显不足。
在教学资源生成方面,模型可根据教师需求推荐课程资源,如初中数学知识点配套的视频与教案,甚至自动生成包含互动设计的完整教案。智能问答系统采用苏格拉底式对话引导思考,解题时通过思维链(CoT)提示展示推理步骤,但多步逻辑问题易出错。评估领域中,客观题自动评分已成熟,主观题评分通过比较判断技术优化,试卷生成系统可按知识点难度组卷。
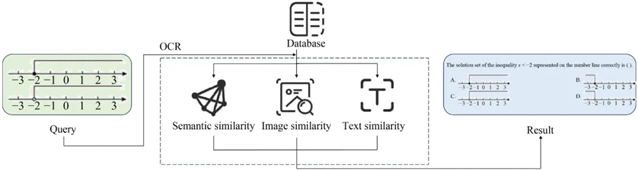
图1 智能问题检索系统
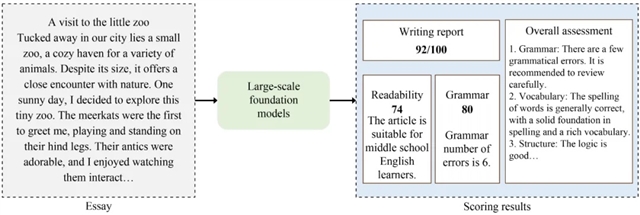
图2 自动评分中的大型语言模型
模型存在一定的现实挑战,认知适配性是主要瓶颈。低龄学生需具象化教学,而模型常输出抽象解释;语文教学中对文本的深层解读不足。多模态处理能力有限,物理电路图、化学装置图等专业图表解析准确率低,生成的教学幻灯片缺乏视觉设计。伦理风险不容忽视,模型可能产生偏见内容,教育数据集中存储存在隐私泄露隐患,过度依赖还可能削弱学生的主动思考能力。
研究指出,未来需构建教育专用多模态数据库,训练模型理解学科图表与实验视频。引入“教学法适配器”,依据维果茨基“最近发展区”理论调整回答难度,为不同年龄段学生提供适配内容。技术上探索情感感知,通过文本分析调整反馈语气;采用联邦学习保障数据安全,开发可解释性插件显示知识来源。最终目标是让LFMs成为“数字苏格拉底”,在知识传递中激发思考,平衡技术效率与教育人文性。
综上,LFMs为K-12教育带来革新可能,但其应用需始终以学生认知发展为核心,在技术创新中坚守教育本质,方能实现智能教育的真正价值。
文章信息
Qiannan Zhu, Mei Wang, Ting Zhang, Hua Huang. Current Trends and Future Prospects of Large-Scale Foundation Model in K-12 Education. Frontiers of Digital Education, 2025, 2(2): 22
https://doi.org/10.1007/s44366-025-0059-6

识别二维码,免费获取原文
作者信息

朱倩男,北京师范大学人工智能学院讲师,主要研究领域为推荐系统、信息检索、知识图谱、图表示学习、负责人的人工智能(可解释性、公平性)。

王玫,北京师范大学人工智能学院副教授,2022年博士毕业于北京邮电大学,研究兴趣包括计算机视觉、深度学习、模式识别等方向。已在IEEE TPAMI、IEEE TIP、PR、CVPR、ICCV等领域内重要期刊和会议发表论文近30篇,其中ESI高被引论文2篇,谷歌学术引用5600余次(截至2025年1月)。主持国家自然科学基金青年基金、中国博士后科学基金面上项目,参与国家重点研发计划、国自然面上、企业横向等多个项目。获邀担任IEEE TPAMI、IEEE TNNLS、IJCV、CVPR、ICCV、ECCV、ACM MM等期刊和会议的审稿人。获得2023年度北京图像图形学学会优秀博士学位论文奖、2022年北京邮电大学优秀博士学位论文奖,入选斯坦福大学“全球前2%顶尖科学家”。

张婷,北京师范大学人工智能学院副教授, 2013年至2017年在微软亚洲研究院视觉计算组实习,2015年获微软学者奖学金,2017年起在微软亚洲研究院视觉计算组工作,2024年起在北京师范大学任教。主要研究领域为计算机视觉,包括视觉表征学习,多模态内容理解与生成等。欢迎感兴趣的老师、研究生和本科生随时通过邮件或微信联系进行学术交流与合作。

黄华,北京师范大学人工智能学院教授,院长。2011年在西安交通大学破格晋升教授。2012年至2020年在北京理工大学计算机学院任教。2022年7月起在北京师范大学人工智能学院任教。主要从事图像/视频处理、计算摄像学、计算机图形学方面的研究工作。主持国家自然科学基金重点项目、国家重点研发计划项目等;发表学术论文百余篇,获授权国家发明专利60余项,部分成果在工业、国防、互联网行业得到应用。2014年获得国家杰出青年基金资助,获得第十四届中国青年科技奖,入选第三批万人计划科技领军人才。兼任“新一代人工智能”科技创新2030重大项目管理专家组成员,JKW XX智能专家组副组长;中国计算机学会常务理事、学术工作委员会副主任;中国图像图形学会常务理事、多媒体专业委员会主任;中国自动化学会理事、副秘书长。
往期回顾
论文解读 | 王学男:DeepSeek的中国式创新重塑中国教育自信
论文解读 | 基于SOLO分类法的大语言模型驱动认知诊断
论文解读 | 陈静远等:利用人工智能知识调整大语言模型
视频推荐 | 浙江大学吴飞教授谈人工智能专业领域教育的垂类大模型
专家观点 | 刘革平:多模态大模型支持的教与学创新
期刊介绍
期刊特点
1. 国际化投审稿平台Editorial Manager方便快捷。
2. 严格的同行评议(Peer Review)。
3. 免费语言润色,有力保障出版质量。
4. 不收取作者任何费用。
5. 不限文章长度。
6. 审稿周期:第一轮平均30天,投稿到录用平均60天。
7. 在线优先出版(CAP)。
8. 通过SpringerLink平台面向全球推广。
在线浏览
https://journal.hep.com.cn/fde
(中国大陆免费下载)
https://link.springer.com/journal/44366
在线投稿
https://www.editorialmanager.com/fode/
邮发代号
80-164
联系我们
fde@hep.com.cn
010-58582344, 010-58581581


特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






