导读
片上光学神经网络(on-chip ONN)因其高带宽、低损耗和低延时的计算特性以及CMOS兼容的制造工艺而受到广泛研究,然而同时满足高密度集成和多任务处理方面仍然存在挑战。
近日,清华大学电子工程系陈宏伟教授领导的研究团队依托于硅基光子衍射结构,开发了一种超紧凑的用于存内光学计算的多任务处理芯片,将大部分网络计算参数嵌入固定的无源光学结构中,同时配合少量电子参数完成多任务处理。推进了光学通用计算框架的研究及下一代人工智能平台的应用。
该成果以“Ultra-compact multi-task processor based on in-memory optical computing”为题发表在Light: Science & Applications。清华大学博士生刘文灿为论文第一作者,清华大学陈宏伟教授为论文通讯作者。
超紧凑型片上光学存内计算架构
研究团队通过对衍射光学计算芯片进行创新设计,使得单一光学芯片不再针对特定任务,而是旨在面对多种任务的输入时作为通用的处理单元,光学芯片即具有固定权重的存内计算单元,搭配轻量的后端网络应对多任务场景,实现“光学固定权重+电学轻量网络”的计算范式。研究团队将训练好的大部分神经网络权重作为亚波长衍射元件集成到芯片中,因此在计算过程中,只需要对输入数据进行调制,从而不再需要从内存中访问网络权重即可在光的传播过程中完成计算。
为了在衍射芯片中实现更高水平的集成和计算密度,同时降低能耗并提高模型精度,研究团队在模型仿真中使用了深度回归神经网络来代替通过麦克斯韦方程对光传播的传统建模。研究团队利用具有复值参数的深度回归神经网络来拟合并预测芯片中光场的传播过程,在预测速度大大提高的基础上,达到与仿真相当的精确水平,并且实现了高达60000参数/平方毫米的计算集成密度。
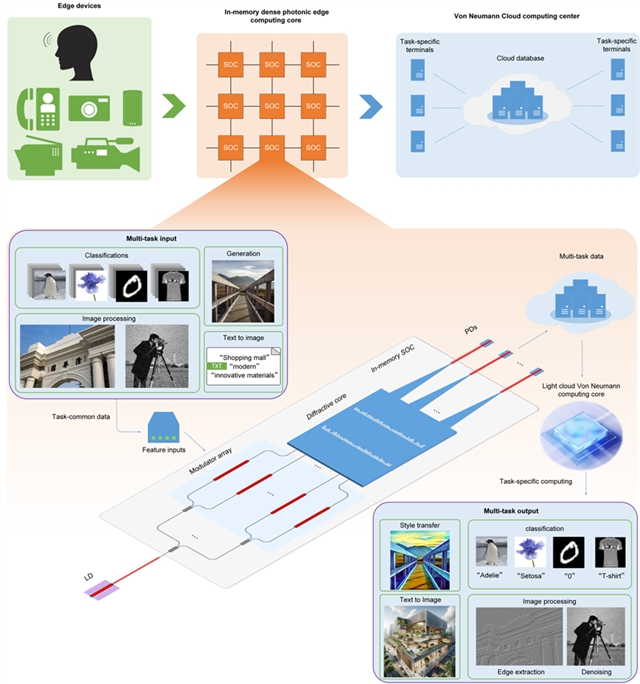
图1:整体系统的处理流程图及在边缘计算架构中的应用示意图
面向多任务处理应用
研究团队在多分类任务和多回归任务上演示了系统的性能,对于多分类任务,对三个独立数据集的进行分类,取得了和电子网络相当的性能,并且将电子耗能计算参数减少了90%。对于多回归任务,系统能够对多组卷积核实现高度拟合,并且在卷积神经网络中以更低的电子参数量实现了更高的计算精度。并且,所提出的系统能够面向边缘端应用,通过一系列内部光学芯片处理多任务输入,从而实现高速和低功耗的数据处理。随后,处理后的数据被传输到云数据库,根据具体的任务要求,在各种终端上执行后续的轻量化计算。
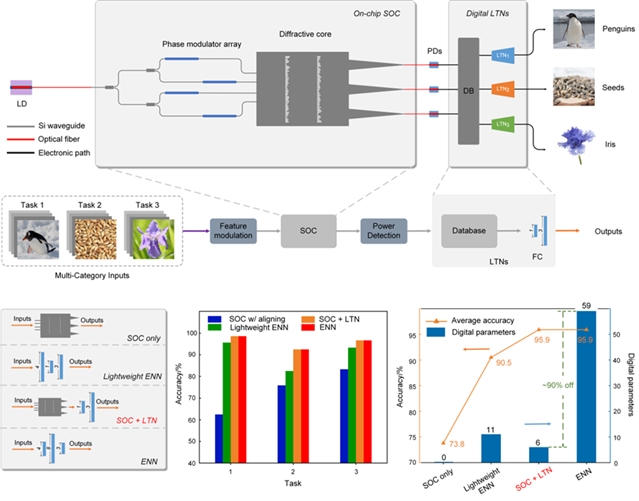
图2:系统对于多分类任务实验的处理流程图及实验结果对比
总结与展望
本研究提出了一种新的片上光学多任务处理器架构,提高了存内光学衍射芯片的集成度和可重构性。将大多数参数固定在超紧凑、存内计算的光学衍射芯片结构中,在实现多任务处理能力的同时,将当前光子芯片的参数集成度、计算容量提高了一个数量级。这项工作不仅推动了光学计算架构的发展,也为未来的大规模高性能计算系统带来了潜力。(来源:LightScienceApplications微信公众号)
相关论文信息:https://doi.org/10.1038/s41377-025-01814-0
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






