
封面图片由中国科学报社科学可视化中心制作
在机器学习任务中,往往需要大量的有标签训练数据以获得更好的性能。但是,在许多实际应用场景中,获取未标注的数据相对容易,标注过程却很困难,通常需要投入大量的时间和经济成本。例如:
1)语音或视频情感估计:情感标签是二维空间(效价、唤醒度)或三维空间(效价、 唤醒度和优势度)中的连续值。虽然记录大量的语音或视频较为容易,但是为每个语音或视频样本打上对应的情感标签却较为困难。这是由于情感是主观、微妙且不确定的,往往需要多位专业评估者评估多次,才能获得准确的标签。因此获取情感标签的工作量非常大,需要消耗大量人力。
2)油井压裂后累计产油量预测:其输入(油井的压裂参数,例如它的位置、射孔的长度、 区域/孔的数量和注入的泥浆/水/砂的体积等)可以在压裂操作期间很容易地记录下来,但要获得真实的标签,例如预测压裂后180天的累计产油量,则必须至少等待180天。因此获取标签的时间成本极高。
在很多这样的问题场景中,如何确定最优的未标注样本进行标注是非常重要的。主动学习(Active learning, AL)可以用于解决此类问题,它通过选择较少的有价值样本进行标注,从而获得性能较好的机器学习模型,减少了数据标注工作。
已有许多用于分类的AL方法相继提出,但回归任务中的AL方法相对较少,且考虑的是较简单的有监督场景,即能够获得少量带标签的样本,建立初始的回归模型,然后根据模型选择后续的样本交给专家进行标注。而无监督主动学习回归算法的采样过程不需要任何真实标签信息,具有重要的研究意义,具体如下:
1)替代随机采样,帮助有监督主动学习回归算法选择更好的初始待打标样本。在没有任何真实标签的情况下,任何有监督主动学习回归算法都必须需要一种无监督的采样算法来选择初始样本进行标注并构建初始回归模型,最简单的方法便是利用随机采样。因此,使用更好的无监督主动学习回归算法可以获得更好的初始模型,简单地提高有监督主动学习回归算法的整体性能。
2)减少人类专家的在线时间。有监督主动学习回归算法需要与人类专家多次交互,返回其真实标签。这要求专家一直保持在线状态,这非常消耗时间和成本,有时甚至很难实现。但是,无监督主动学习回归算法可以一次性选择出所有的待打标的候选样本,人类专家可以一次完成标记工作,这样可以进一步减小标注时间成本。
3)在训练样本数量较少的条件下提升回归模型性能。在特殊情况下,我们的资源仅足以标记极少量样本(例如5个样本),若使用有监督主动学习回归算法用于训练初始回归模型的标记样本会更少(例如3个标记样本),这样初始模型会非常粗糙,甚至会误导另外2个待打标样本的选择,降低最终训练得到的回归模型的性能。而若使用无监督主动学习回归算法,则不会存在这个问题,因此在训练样本数量极少的情况下,在回归问题中应用无监督主动学习回归算法可能比应用有监督主动学习回归算法获得更好的效果。
有监督主动学习回归算法和无监督主动学习回归算法的流程图见下图。

因此,本文提出一种基于信息性-代表性-多样性 (Informativeness-representativeness-diversity, IRD) 的主动学习回归算法。通过同时考虑主动学习中的3个重要标准:信息性、代表性和多样性,在没有任何标签信息的情况下,确定要查询标注的初始样本,从而构建较好的线性回归模型。经过大量的实验验证表明了本文所提出的IRD方法的优越性能。
假设M为要选择的样本数量,d为特征维度,IRD算法考虑了在三种情形下的实现(M=d+1,Md+1),这里主要介绍在第一种情形下的实现。
对于d维特征数据,通常需要选择至少d+1个样本构造线性回归模型,当d=2时,IRD算法的基本思想如下图所示:
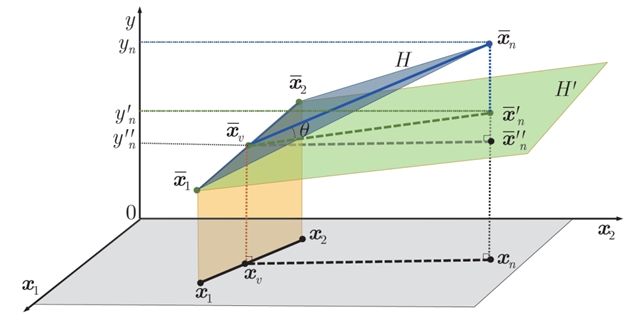
d=2时 IRD算法图示


上述方法是在前d个样本确定的情况下选择第(d+1)个样本。本文还提出一种交替优化方法,对所有d+1个样本进行优化选择。
另两种情形(Md+1)下的IRD算法核心是一致的。
实验部分,在来自于不同应用领域的12个数据集和3种不同的线性回归模型(RR、LASSO和线性SVR)上进行了大量实验,充分验证了本文提出方法的有效性。(来源:科学网)
相关论文信息:DOI: 10.16383/j.aas.c200071






