想象一下未来的智能体,无论是作为你的虚拟助手,还是帮你操控终端的机器人、自动驾驶,它们都必须具备超越简单看图识物的能力:不仅要“看懂”(精确感知环境),更要“想明白”(基于视觉信息进行复杂逻辑推断、关系理解和行为预测)。而强化学习(RL),正是让多模态模型实现这些核心能力的关键路径。
但在当前,在多模态强化学习领域,视觉感知和视觉推理任务往往被独立或松散地处理,这就像两条互不相干的铁路,限制了信息的共享和协同优化的潜力。这正是V-Triune诞生的初衷——打破界限,让它们在一个统一的框架下协同工作。
5月28日,《中国科学报》从国内多模态AI独角兽企业MiniMax获悉,其技术团队日前正式开源了其自主研发的首个视觉强化学习(Visual RL)统一框架——V-Triune。这项技术在国际权威基准测试MEGA-Bench上表现亮眼,32B模型性能提升高达14.1%,展现了中国AI技术创新的魅力。
“V-Triune的核心贡献在于,首次提出了一个能够统一处理视觉感知和视觉推理任务的强化学习系统。”MiniMax相关技术负责人告诉《中国科学报》,它就像一位高明的指挥家,让视觉语言模型(VLM)在一个训练流程中同时学习这两类任务,从而大幅提升视觉信息的综合利用效率和模型的泛化能力。
“V-Triune的开源,弥补了传统RL方法无法兼顾多重任务的空白。”该技术负责人表示。
据介绍,V-Triune在技术实现上有不少巧思妙想的设计。例如,它采用“样本级数据格式化”,可以像“翻译官”一样让来自不同任务的数据以统一且灵活的格式接入;它还把奖励的评判逻辑抽离出来,形成一个个独立的“裁判员”模块,这种模块化设计让整个系统就像搭积木一样,轻松扩展新任务。在算法层面,技术团队为感知任务引入了一种新颖的动态IoU奖励机制,它能根据训练的进展,自适应地调整奖励阈值的“严格度”,这也为实现更稳定、更可扩展的训练过程提供了关键保障。实测显示,在涵盖440项真实世界视觉任务的权威 基准测试(MEGA-Bench Core)上,基于V-Triune训练的Orsta模型取得了显著突破,有力证明了统一技术路径在提升VLM综合视觉能力方面的巨大有效性和潜力。
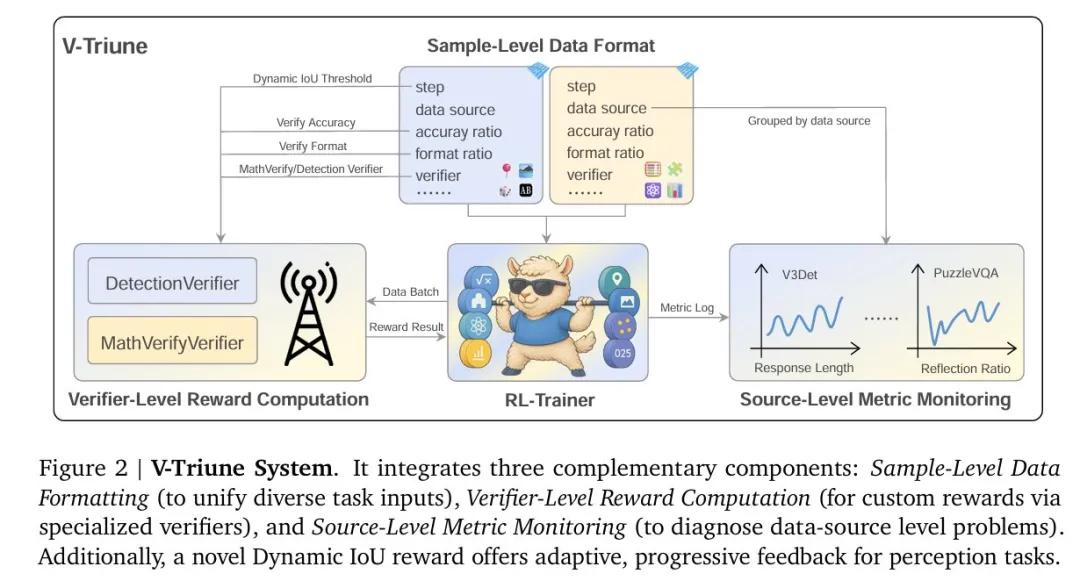 V-Triune 系统图示。图源:技术论文
V-Triune 系统图示。图源:技术论文
?
《中国科学报》在论文作者一栏发现,MiniMax创始人兼CEO闫俊杰也参与了这项研究。据介绍,本次V-Triune所呈现的工作,是创业团队MiniMax在构建未来大规模多模态Agent模型视觉推理能力方面的一次有益探索和重要技术储备。
“这项工作为后续开发更强大、更通用、更聪明的视觉智能系统,提供了重要的思路和组件。”前述技术负责人表示。
相关信息:
技术报告(论文):https://arxiv.org/pdf/2505.18129
开源代码:https://github.com/MiniMax-AI/One-RL-to-See-Them-All
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






