如何让模型算法仅利用“少量、低质量的有标注样本”,就能实现或接近“大量、高质量、有标注数据的样本”所能达到的结果,是小样本学习领域的关键问题。为此,之江实验室前沿基础研究中心博士后邵帅为小样本计算研究提出了新思路。
他的思路是,通过利用已有基础模型资源的优势潜力,实现下游任务中小样本测试数据的精准分类。近日,该成果以《面向开放世界小样本学习的基础模型联合协作方法》(Collaborative Consortium of Foundation Models for Open-World Few-Shot Learning)为题,在计算机视觉领域国际顶级会议AAAI上发表。
邵帅认为,直接使用冻结参数的基础模型能够为计算研究节约大量时间和资源。他将那些已经训练好的基础模型比作“一本编纂好的百科全书”,将使用基础模型技术解决小样本学习问题的过程比作“查阅百科全书中与小样本学习相关的部分”。只是,是“从第一页开始慢慢找”还是“通过目录或全文检索”,不同检索方式带来的计算效率天差地别。
为此,邵帅等人提出了基于多种基础模型的协作方法(CO3),探索利用CLIP、GPT-3、DINO 和DALL-E四种基础模型开启智能计算。
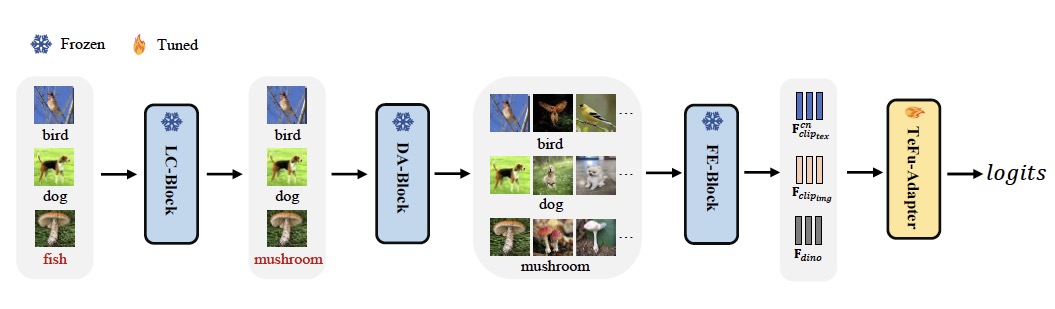 基础模型协作方法流程图。图源:论文
基础模型协作方法流程图。图源:论文
?
在具体操作过程中,他们设计了四类模块分别用于模型间整合衔接。邵帅介绍说,首先将小样本数据输入标签校正块(LC-Block),通过设计原型结构,来对数据进行降噪。随后将校正数据送入数据增强块(DA-Block),增强模型在数据上的泛化性能,以获得更丰富的训练数据。接着,将清理后的原始数据和扩充数据输入特征提取块(FE-Block),得到数据的文本和图像特征。最后将这些特征与特别设计的TeFu-Adapter相融合调优,进一步减轻噪声标签对模型的影响,增强该方法的鲁棒性。
目前,该方法已在多个数据集上进行了大量实验,证明了CO3的可行性,甚至在数据质量越低、可用标签样本越少的情况下表征能力越优秀。如在噪声比例从0.0到1.0的区间范围内,每类只有一个可用标签样本的情况下,CO3在数据表达的准确性上能稳定达到62%以上,兼顾了性能与成本效率的平衡。
“如何弥合小样本学习技术与现实应用的缝隙,是我们下一阶段要攻克的难题。”邵帅表示,在之江实验室智能算力基础设施的支持下,未来他将进一步提高小样本学习算法的泛化能力,探索回应真实世界的需求场景,不断突破智能计算的极限。
注:相关文章发表于The Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI-24),为会议发表论文
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






