南开新闻网讯(记者 高雨桐)2024年伊始,Open AI(美国开放人工智能研究中心)公司发布首个AI(人工智能)文字生成视频大模型Sora,通过计算机视觉技术模拟现实世界的动态变化,可以一次生成60秒流畅逼真的视频,被视为继ChatGPT之后人工智能技术的又一重大突破。但从实测Sora的一些“翻车”视频中可以看出,AI仍然存在着无法快速、准确“理解”物理世界的困难。
近日,南开大学、南开国际先进研究院(深圳福田)教授程明明团队一项国际联合研究成果MDT(Masked Diffusion Transformer),相比Sora核心组件DiT(Difffusion Transfomer)训练速度提升10倍以上,再次刷新SoTA(最佳)图像生成质量和学习速度,实现了ImageNet benchmark(大型图像分类数据集性能测试)上1.58的FID score(图片质量的度量),超过Meta、Nvidia等知名公司提出的模型。研究团队也已将MDT源代码全部开放。
以Sora核心组件之一DiT为代表的扩散模型,可以实现“无中生有”得到一张高质量图像,是近年来人工智能技术最大亮点之一。但DiT往往难以高效地学习图像中物体各部分之间的语义关系,这一局限性导致了训练过程的低收敛效率。同时,更大的模型规模和数据规模也会消耗大量的算力能耗,导致训练成本飙升。
“以DiT生成一张小狗图像举例,它在第5万次训练步骤时已经学会生成狗的毛发纹理,然后在第20万次训练步骤时才学会生成狗的一只眼睛和嘴巴,却漏生成了另一只眼睛。即使在第30万次训练步骤时,DiT生成的狗的两只耳朵的相对位置也不是非常准确。”程明明说,“简单来说,就像做阅读理解时忽视了上下文的语义关系,导致生成图像中经常出现偏差需要反复修正,大幅增加了训练成本。”
?
图1:DiT在第30万次训练步骤中仍不能准确生成图像
如何降低训练成本、提升训练效率?南开大学、南开国际先进研究院(深圳福田)教授程明明、博士研究生高尚华,以及冬海集团人工智能实验室(Sea AI Lab)博士研究生周攀和新加坡工程院院士、IEEE/ACM Fellow、昆仑万维2050研究院院长颜水成共同提出了解决方法。通过在扩散训练过程中引入上下文表征学习,能够利用图像物体的上下文信息,重建不完整输入图像的完整信息,从而学习图像中语义部分之间的关联关系,提升图像生成的质量和学习速度。成果相关论文"Masked Diffusion Transformer is a Strong Image Synthesizer"(成果大幅提升扩散生成模型的训练速度和生成质量)已在计算机视觉顶级会议ICCV 2023(计算机视觉国际大会)发表。
?
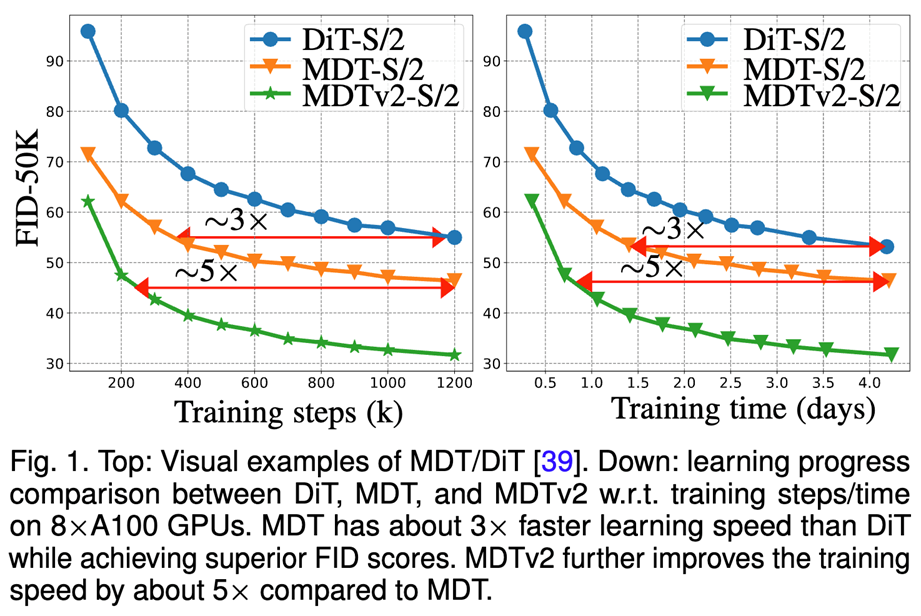
图2:DiT-S/2基线、MDT-S/2和MDTv2-S/2在不同训练步骤、训练时间下的FID性能
近日,研究团队又将MDT升级到v2版本,在MDTv2中引入了一个更为高效的宏观网络结构,进一步优化了学习过程,同时通过采用更快的Adan优化器、扩大掩码比率等更优的训练策略来进一步加速模型的训练过程。实验结果证明,通过视觉表征学习增强对物理世界的语义理解,能够提升生成模型对物理世界的模拟效果。
程明明说,“希望我们的工作能够激发更多关于统一表征学习和生成学习的工作,提升AI大模型的‘智慧’水平,解决更多场景的现实问题。”
论文地址:https://arxiv.org/abs/2303.14389
(原标题:南开团队开源MDTv2!可让Sora核心组件DiT训练提速10多倍)
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。