|
|
|
|
|
FDE 论文解读 | MathEval:评估大语言模型数学推理能力的综合基准 |
|
|
论文标题:MathEval: A Comprehensive Benchmark for Evaluating Large Language Models on Mathematical Reasoning Capabilities
期刊:Frontiers of Digital Education
作者:Tianqiao Liu , Zui Chen , Zhensheng Fang , Weiqi Luo , Mi Tian , Zitao Liu
发表时间:25 Jun 2025
DOI:10.1007/s44366-025-0053-z
微信链接:点击此处阅读微信文章

在当今的教育领域,数学不仅仅是一门学科,更是培养学生逻辑思维、问题解决能力的重要工具。然而,随着人工智能技术的快速发展,尤其是大语言模型(LLMs)的崛起,教育界开始思考:这些“聪明的机器”是否也能像人类一样进行数学推理?它们能否帮助教师减轻教学负担,甚至为学生提供个性化的学习支持?
近年来,公司、学界推出的各类大模型正展现出强大的潜力。它们不仅能理解和生成自然语言,还能在数学问题解决中表现出色。然而,尽管这些技术在数学教育中的应用前景广阔,如何全面、准确地评估它们的数学推理能力,仍然是一个亟待解决的问题。
想象一下,如果未来的课堂上,AI能够帮助各个年龄段的学生解答各类复杂的数学题,提供个性化的学习建议,那将是多么令人兴奋的场景!但在此之前,我们需要一个可靠的评估工具,确保这些AI模型不仅“聪明”,而且“可靠”。
研究论文
近日,好未来—暨南大学联合研发团队提出了MathEval,一个涵盖22个数据集的综合基准测试框架,旨在全面评估LLMs在数学推理任务中的表现。MathEval不仅涵盖了从基础算术到高等数学的多种数学问题,还包含了中英文两种语言的问题,确保了评估的多样性和全面性。
MathEval的核心创新在于其三大组件:数学场景、提示适应和基于LLM的评估。首先,MathEval通过整合22个数据集,涵盖了从小学到高中的不同教育阶段的数学问题,确保了评估的广泛性。其次,MathEval采用了针对不同模型和数据集的提示模板,确保评估的公平性和适应性。最后,MathEval利用GPT-4作为自动化管道进行答案提取和比较,避免了传统基于规则的方法在复杂数学问题上的不足。
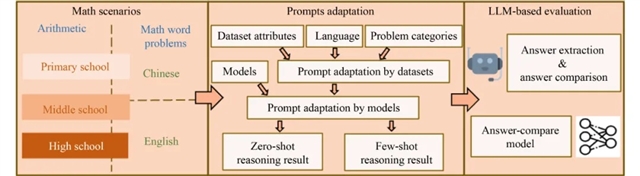
图1 MathEval 的核心组件
研究团队还开发了一个基于DeepSeek-Math-7B训练的开源评测模型,用于在没有GPT-4访问权限的情况下进行精确的答案验证。为了确保评估的公正性,MathEval还引入了每年更新的中国高考数学题(如2023年和2024年的高考题),以防止测试数据的污染,确保评估结果能够真实反映模型的数学推理能力。
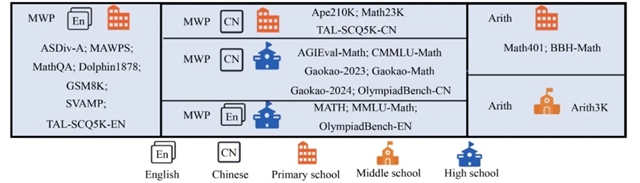
图2 MathEval 框架中使用的 22 个数据集概述
通过对52个模型的评估,MathEval展现了一份各维度数学能力的榜单,并为LLMs的数学推理能力提供了一个公正、全面的评估框架。这一框架不仅推动了LLMs在数学领域的持续改进和实际应用,还为教育工作者和研究人员提供了宝贵的参考,帮助他们更好地理解和利用AI技术在数学教育中的潜力。
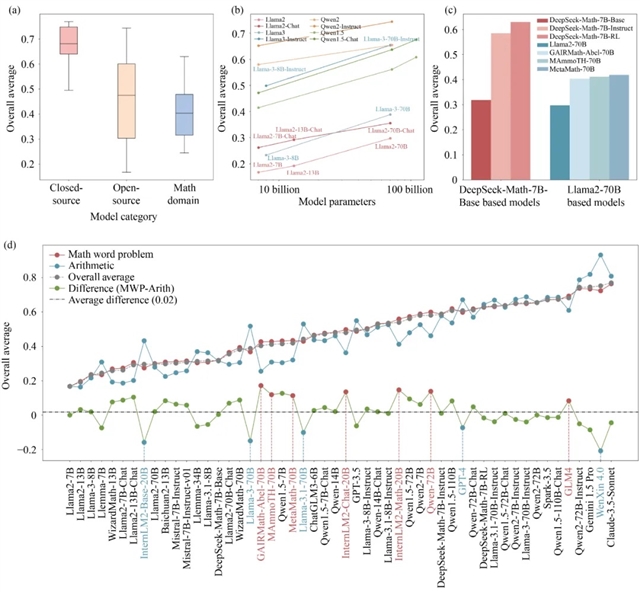
图3 MathEval 评估结果
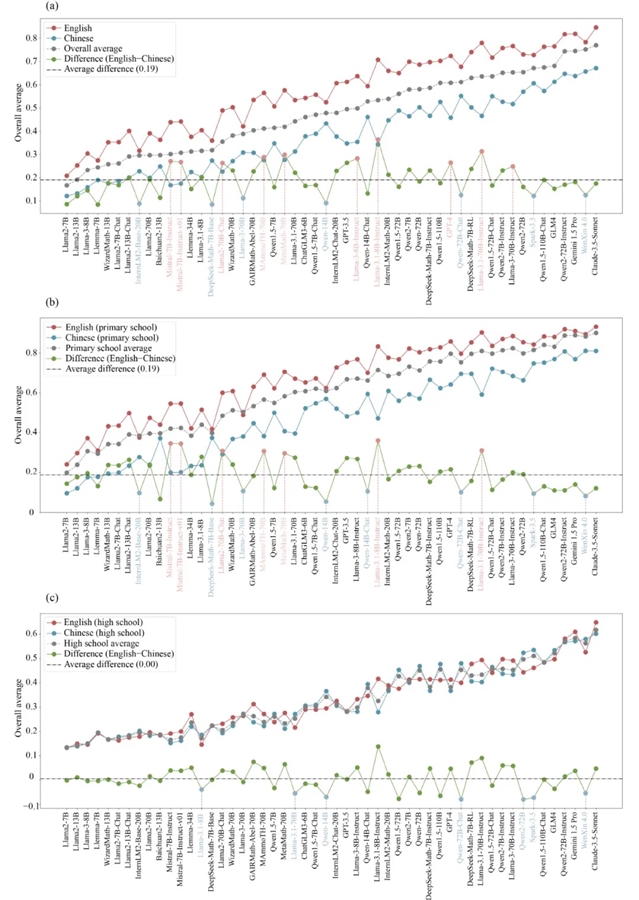
图4 中英文数学能力的比较
文章信息
Tianqiao Liu, Zui Chen, Zhensheng Fang, Weiqi Luo, Mi Tian, Zitao Liu. MathEval: A Comprehensive Benchmark for Evaluating Large Language Models on Mathematical Reasoning Capabilities. Frontiers of Digital Education, 2025, 2(2): 16
https://doi.org/10.1007/s44366-025-0053-z

识别二维码,免费获取原文
作者信息

刘天乔是好未来教育集团的自然语言处理算法专家。他的研究兴趣包括可控自然语言生成、大型语言模型推理以及人工智能在教育中的应用。在WWW、SIGIR、AAAI、EMNLP和AIED等顶级会议上发表了10多篇论文。此外,他拥有超过10项国家专利,还在多个全国性竞赛中获得一等奖,特别是在Ubicomp 2020时间序列分类挑战赛和NeurIPS 2020教育挑战赛中取得了第一名。

陈醉,上海科技大学在读硕士研究生,硕士期间在好未来教育集团进行研究学习,主要研究重点聚焦在大语言模型在数学推理领域的提升与应用,并在ICLR、AAAI、EMNLP等国际顶级会议上发表过相关文章。

方振圣,目前在好未来担任自然语言处理工程师,专注于检索和大模型测评领域,致力于提升信息检索系统的性能及大模型的评价方法。

罗伟其,暨南大学二级教授、博士生导师、教育部信息化专家组专家、国家督学、广东省人民政府参事、暨南大学广东智慧教育研究院名誉院长、广东省教育厅原厅长。主要研究方向是教育人工智能、机器学习、大数据、数据安全和教育信息化。在国内国际学术期刊上公开发表80多篇论文,曾获广东省科学技术二等奖六次,其中二次为第一完成人,四次为第二完成人。

田密,好未来集团CTO、清华大学-好未来智能教育信息技术联合研究中心主任、四川大学-好未来“汇智未来”研究中心主任。毕业于北京航空航天大学计算软件与理论专业,师从李德毅院士,研究方向为不确定性人工智能。长期从事搜索引擎、LBS 大数据挖掘、在线教育AI技术等研究工作,致力于打造中国最懂教育的技术体系,主持参与“智慧教育人工智能开放创新平台”“教育大数据驱动的个性化学习关键技术研究与示范应用”等多个国家重大专项。担任好未来集团 CTO 以来,他带领集团研发团队4000人,建立了技术中台、内容中台,将视觉、语音、NLP 等 AI 技术广泛应用于公司的各个业务,并研发了国内千亿级别数学大模型学而思九章大模型,也是国内首批拿到教育大模型牌照的大模型。

刘子韬博士,现任暨南大学广东智慧教育研究院教授,博士生导师,研究院院长,主要研究方向是人工智能技术在教育场景的应用。在NeurIPS等人工智能领域顶级会议和期刊上发表论文100余篇,国内外授权发明专利40余项。刘子韬博士主持和参与国家重点研发计划课题、科技创新2030-“新一代人工智能”重大项目等多项科研工作。同时,刘子韬博士担任国际人工智能教育协会执行委员和第25届国际人工智能教育大会(AIED 2024)程序主席,其研究成果获得了包含CCTV新闻联播、CCTV正点财经、人民网、新华网等多家新闻媒体的报道。
往期回顾
论文解读 | 基于SOLO分类法的大语言模型驱动认知诊断
论文解读 | 陈静远等:利用人工智能知识调整大语言模型
论文解读 | 佟佳睿:基于神经符号AI智能体和大语言模型的个性化AI教育
论文解读 | 大学生人工智能素养评价体系的构建——基于武汉大学
论文解读 | 学习的演变:评估 GenAI 对高等教育变革的影响
期刊介绍
期刊特点
1. 国际化投审稿平台Editorial Manager方便快捷。
2. 严格的同行评议(Peer Review)。
3. 免费语言润色,有力保障出版质量。
4. 不收取作者任何费用。
5. 不限文章长度。
6. 审稿周期:第一轮平均30天,投稿到录用平均60天。
7. 在线优先出版(CAP)。
8. 通过Springer Link平台面向全球推广。
在线浏览
https://journal.hep.com.cn/fde
(中国大陆免费下载)
https://link.springer.com/journal/44366
在线投稿
https://www.editorialmanager.com/fode/
邮发代号
80-164
联系我们
fde@hep.com.cn
010-58582344, 010-58581581


特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






