|
|
|
|
|
FCS 前沿研究:用于无监督域适应的自适应标签过滤学习 |
|
|
论文标题:Self-adaptive label filtering learning for unsupervised domain adaptation(用于无监督域适应的自适应标签过滤学习)
期刊:Frontiers of Computer Science
作者:Qing TIAN, Heyang SUN, Shun PENG, Tinghuai MA
发表时间:15 Feb 2023
DOI:10.1007/s11704-022-1283-6
微信链接:点击此处阅读微信文章
原文信息
标 题:
Self-adaptive label filtering learning for unsupervised domain adaptation
发表年份:
2023年
原文链接:
https://journal.hep.com.cn/fcs/EN/10.1007/s11704-022-1283-6
引用格式:
Qing TIAN, Heyang SUN, Shun PENG, Tinghuai MA. Self-adaptive label filtering learning for unsupervised domain adaptation. Front. Comput. Sci., 2023, 17(1): 171308
公众号推文链接:
文章精要 | 南京信息工程大学田青教授团队:用于无监督域适应的自适应标签过滤学习
01 导读
作为一种新的机器学习范式,无监督域适应(Unsupervised Domain Adaptation, UDA)旨在利用相关但分布不同的源域(Source Domain)的知识来辅助训练一个对无标记的目标域(Target Domain)有效的模型。现有大多数无监督域适应方法通过预训练模型来获取目标域的伪标签从而进行类级别的分布对齐,但现有的为标签编码的方式中,硬标签过度置信而软标签往往含有噪声,都容易影响模型的表现。因此,如图1所示,本篇论文提出了一种自适应的标签过滤学习(SALFL)方法来解决这个问题。具体来说,本篇论文设计了一种基于图的随机游走策略来预测伪标签然后通过所提出的自适应标签过滤机制对其进行提炼。更进一步地,在新获得的伪标签基础之上,本篇论文提出了一种更通用的联合分布对齐方法并将整体方法推广到深度算法框架中。

图1. SALFL框架示意图。概率标签上不同颜色表示对应不同的类别。
02 相关工作
如导读中所述,域适应问题的关键之处在于寻找源域和目标域之间的相似性,从而利用源域的知识来辅助目标域的学习,因此两类方法得到了较多的关注。
基于特征的统计对齐方法是一种较为有效的方法,举例来说,测地线流核(GFK)方法[1]通过度量最优维数将所得跨域子空间进行积分,以从统计方法上建模域偏移。尽管该方法优雅且有效,但灵活性不足难以进行拓展。之后,子空间对齐(SA)[2]方法将源域特征转换至目标域空间,这种方式在一定程度上对齐了域偏移但忽略了目标域空间的私有部分。实际上,大多数现有UDA方法试图通过共享子空间来消除域差异。基于此,最大均值差异嵌入(MMDE)[3]方法对MMD进行最大方差展开(MVU),从而得到一个对齐后的低维潜在子空间。类似地,迁移成分分析(TCA)[4]方法通过MMD最小化源域和目标域的散点,将其投影至公共空间中。除了总体分布对齐外,联合域适应(JDA)[5]方法将边缘MMD与条件MMD进行结合以更好地进行域对齐。为了解决UDA中的任务不平衡问题,迁移联合匹配(TJM)[6]方法对跨域样本进行重新加权并进行联合特征匹配。后来,平衡域适应(BDA)[7]方法通过在边际分布和条件分布对齐之间引入一个平衡因子,获得了比TJM更好的结果。为了利用更多的判别知识,联合几何和统计对齐(JGSA)[8]方法将目标域、源域的分布方差以及跨域分布散差联合建模为一个统一的目标。域不变类判别(DICD)[9]方法通过测量类内相似性和类间差异性来学习UDA的类判别表示。
除此之外,几何结构学习因在数据结构挖掘上的有效性,在UDA任务中被广泛使用。例如,流行嵌入分布对齐(MEDA)[10]方法被设计为通过最小化格拉斯曼流形上的数据结构风险来学习一个领域不变的UDA分类器。判别性结构意识域适应(DGA-DA)[11]方法通过几何结构学习推断目标域标签来执行UDA。然而由于几何结构学习往往通过迭代优化策略实现,所以每轮生成的伪标签质量对下一轮迭代至关重要,低置信度的伪标签很容易造成累计误差从而影响整个模型的性能表现。不幸的是,这一问题在上述讨论的方法中均被忽略。
实际上,在无监督域适应中,伪标签的问题也得到了一定的关注。具体来说,置信正则自训练(CRST)[12]方法通过置信正则化来提升软伪标签的平滑性,从而获得更可信的预测,但所嵌入的正则化损失难以优化,也难以转移到其他模型。此外,对比适应网络(CAN)[13]方法通过置零来过滤远离集群中心的点和类。虽然该方法可以减轻噪声伪标签的干扰,但它存在伪标签过置信问题,而这篇论文提出的SALFL方法可以同时处理这两个问题。渐进特征对齐网络(PFAN)[14]方法利用从易到难的转移策略(EHTS)逐步选择简单的样本进行域对齐。虽然每个样本的置信度保持不变,但由于所选样本组成的局部域具有较高的置信度,更易于对齐。与这类迭代和局部选择样本的策略不同,这篇论文根据所提自适应标签滤波学习策略对每个目标域样本都进行有效的提纯从而使所有样本都更加可靠。
03 主要方法
问题定义
在UDA场景中,给定一个有标签的源域数据集 ,其中,
,其中, 表示第
表示第 个源域样本实例,
个源域样本实例, 表示其对应的标签。UDA的目标是为无标记的目标域
表示其对应的标签。UDA的目标是为无标记的目标域 样本
样本 分配标签,其中,
分配标签,其中, 表示第
表示第 个目标域样本实例。源域和目标域共享相同的特征空间
个目标域样本实例。源域和目标域共享相同的特征空间 和标记空间
和标记空间 。除此之外,每个域的边缘和条件分布均不相同,即
。除此之外,每个域的边缘和条件分布均不相同,即 和
和 。
。
基于图的随机游走
这篇论文首先引入了一种标签预测算法,它在图上采用一种特殊的随机游走的方式,该算法允许未标记点(即目标域数据)在邻域相似度图的指导下进行随机游走,从标记点(即源域数据)中寻找标签信息。该图结构的邻接矩阵 的每个元素可计算如下:
的每个元素可计算如下:

其中 度量
度量 和
和 之间的非负相似性,
之间的非负相似性, 表示方差,表示域中最相近的
表示方差,表示域中最相近的 个近邻组成的集合。每一次的随机游走变换可以计算如下:
个近邻组成的集合。每一次的随机游走变换可以计算如下:

其中 表示近邻图的路径权重矩阵计算,度矩阵D是一个每个元素为
表示近邻图的路径权重矩阵计算,度矩阵D是一个每个元素为 的对角阵。除此之外,对角矩阵
的对角阵。除此之外,对角矩阵 和
和 各自由方向系数
各自由方向系数 和
和 构成。如果第
构成。如果第 个点无标记(即目标域样本),定义
个点无标记(即目标域样本),定义 这样可以使得这个点进行随机游走,反之如果这个点有标记(即源域样本),定义
这样可以使得这个点进行随机游走,反之如果这个点有标记(即源域样本),定义 这样可以约束这个点停在原地。
这样可以约束这个点停在原地。
在近邻图中,每个点根据变换矩阵 从起始点进行随机行走,直到其连续两次到达同一点。定义
从起始点进行随机行走,直到其连续两次到达同一点。定义 ,
, 表示在第
表示在第 个点在第
个点在第 个点上停止随机游走。那么,随机行走的过程可以描述为:
个点上停止随机游走。那么,随机行走的过程可以描述为:

其中 表示第
表示第 个点在第
个点在第 步停留在第
步停留在第 点上的概率。更进一步地,软标签矩阵
点上的概率。更进一步地,软标签矩阵 可以被计算为
可以被计算为 。
。
自适应标签过滤学习
通过上述的随机游走过程得到的目标域预测标签对后续的域分布对齐至关重要。下一步是选择用硬标签或软标签来进行标签编码。然而,硬标签过度自信,当出现误分类样本时很容易误导模型,导致负迁移。同样地,软标签所携带的噪声标签也容易造成模型的混淆。为了克服这一问题,本文通过自适应标签过滤学习来滤除目标域的错误或有噪声伪标签。令 分别表示源域和目标域的特征,
分别表示源域和目标域的特征, 表示通过随机行走预测得到的第i个目标域实例的伪标签编码向量,同时
表示通过随机行走预测得到的第i个目标域实例的伪标签编码向量,同时 为其属于第
为其属于第 个类的概率。首先,通过最近邻分类器为目标域的每个实例
个类的概率。首先,通过最近邻分类器为目标域的每个实例 重新分配标记:
重新分配标记:

其中 表示两点之间的欧氏距离,
表示两点之间的欧氏距离, 表示源域第
表示源域第 个类的类中心。然后,按照如下方式更新(提纯)伪标签:
个类的类中心。然后,按照如下方式更新(提纯)伪标签:

其中,当 时,单位阶跃函数
时,单位阶跃函数 ,否则为0。定义函数非零
,否则为0。定义函数非零 ,令它返回向量
,令它返回向量 中的非零值的数量。如图2所示,对于一个由自适应标签过滤策略所提纯后的标签
中的非零值的数量。如图2所示,对于一个由自适应标签过滤策略所提纯后的标签 ,如果
,如果 ,则认为它为置信标签(如图2(a)),该标签可以为后续类级别对齐提供更准确的分类信息。如果
,则认为它为置信标签(如图2(a)),该标签可以为后续类级别对齐提供更准确的分类信息。如果 ,则认为它为模糊标签(如图2(b)),虽然无法提供更准确的分类信息,但该标签可以有效避免误分类造成的累计误差,并且免除了其它微小噪声的干扰。本章将所提的提纯过程叫做自适应标签过滤,它利用源域分布的质心来近似目标域的质心,是一种目标域无监督方式。实际上,这种自适应标签过滤学习过程可以看作是基于标签选择的软标签编码和硬标签编码的自动组合,置信的标签使用硬标签的形式,而模糊的标签使用软标签的形式,改策略可以有效地缓解负迁移的产生。
,则认为它为模糊标签(如图2(b)),虽然无法提供更准确的分类信息,但该标签可以有效避免误分类造成的累计误差,并且免除了其它微小噪声的干扰。本章将所提的提纯过程叫做自适应标签过滤,它利用源域分布的质心来近似目标域的质心,是一种目标域无监督方式。实际上,这种自适应标签过滤学习过程可以看作是基于标签选择的软标签编码和硬标签编码的自动组合,置信的标签使用硬标签的形式,而模糊的标签使用软标签的形式,改策略可以有效地缓解负迁移的产生。

图2. 过滤后的伪标签示意图。
基于过滤标签的域适应一般形式
为了进行域分布对齐,本篇论文基于MMD进行联合分布对齐,其边缘分布对齐可以定义为 ,其中
,其中 是子空间投影矩阵。令
是子空间投影矩阵。令 ,
, ,
, ,则MMD矩阵为
,则MMD矩阵为 。与其他方法不同的是,为了有效地将过滤后的标签与条件MMD度量相结合,本篇论文重新定义了跨域的条件分布距离度量为
。与其他方法不同的是,为了有效地将过滤后的标签与条件MMD度量相结合,本篇论文重新定义了跨域的条件分布距离度量为 ,其中
,其中 ,
, ,
, 和
和 分别是源域和目标域通过随机游走获得的标签。重新定义的条件MMD矩阵
分别是源域和目标域通过随机游走获得的标签。重新定义的条件MMD矩阵 的每个元素可以计算如下:
的每个元素可以计算如下:

虽然联合域分布对齐可以增加模型对目标域的判别性,但它只关注来自同一类别的数据,而忽略了来自相同域的不同类间的可判别性。为此,本篇论文最大化这两个领域的不同类别集合之间的可区分性。具体来说,在联合域 中,用
中,用 表示第
表示第 个类的组成的子域,
个类的组成的子域, 表示除第
表示除第 个类外的所有其它类别的组成的子域。然后,类别间的差异判别可以表达为
个类外的所有其它类别的组成的子域。然后,类别间的差异判别可以表达为 ,其中,
,其中, 表示判别矩阵,它的每个元素定义为:
表示判别矩阵,它的每个元素定义为:

最大化 可以有效地扩大源域和目标域的类别之间的距离,进一步提高了模型的判别能力。
可以有效地扩大源域和目标域的类别之间的距离,进一步提高了模型的判别能力。
总体目标函数及优化
综合考虑上述所有组成部分,SALFL方法的最终目标可以整合如下:

其中 为超参数,
为超参数, 为中心矩阵。整体目标函数的优化由两部分组成,首先是通过基于图的随机游走进行标签预测:
为中心矩阵。整体目标函数的优化由两部分组成,首先是通过基于图的随机游走进行标签预测:

第二个需要优化的部分是基于标签过滤的判别性域适应。将主成分分析(PCA)约束嵌入增广拉格朗日方法中,最终目标函数可以被改写为

最终,该公式可以通过广义特征值分解求解,最优投影矩阵由其前个最小的特征向量构成。
04 实验结果
为了验证SALFL模型的有效性,作者在Office-Caltech-10、Office-Home、Office-31等域适应标准数据集上进行了实验,其实验结果如下:
表1. 在Office-Caltech-10数据集上使用SURF特征的分类性能。

表2. 在Office-Caltech-10数据集上使用图片特征的分类性能。
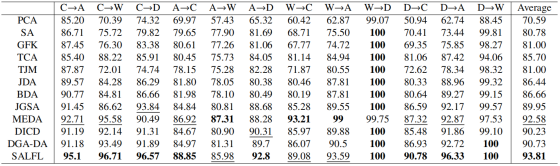
表3. 在Office-Home数据集上使用ResNet-50特征的分类性能。

可以看出,SALFL方法在不同的数据集、不同的特征类型上,相较于其他方法其准确率有实质性的提升。除此之外,这篇论文所提的自适应的标签过滤学习方法可以与大多数现有域适应方法结合使用,其与深度方法结合使用的结果如下所示:
表4. 在Office-31数据集上与不同深度方法相结合的分类性能。

可以发现,现有域适应方法在与所提标签过滤学习方法相结合后,性能较原模型有了一定的提升。为了进一步验证模型的有效性,作者还进行了假设检验,如图3所示,可以发现所提SALFL方法相较其他方法有一定的显著性。
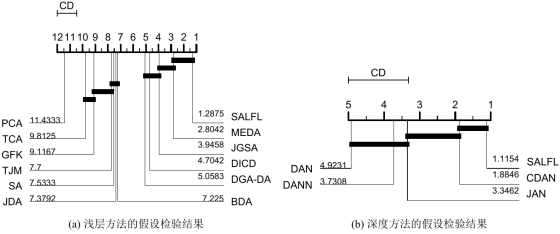
图3. 在Office-31数据集上与不同深度方法相结合的分类性能。
参考文献
[1] Gong B, Shi Y, Sha F, et al. Geodesic flow kernel for unsupervised domain adaptation. 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012: 2066-2073.
[2] Fernando B, Habrard A, Sebban M, et al. Unsupervised visual domain adaptation using subspace alignment. Proceedings of the IEEE international conference on computer vision. 2013: 2960-2967.
[3] Pan S J, Kwok J T, Yang Q. Transfer learning via dimensionality reduction. AAAI. 2008, 8: 677-682.
[4] Pan S J, Tsang I W, Kwok J T, et al. Domain adaptation via transfer component analysis. IEEE transactions on neural networks, 2010, 22(2): 199-210.
[5] Long M, Wang J, Ding G, et al. Transfer feature learning with joint distribution adaptation. Proceedings of the IEEE international conference on computer vision. 2013: 2200-2207.
[6] Long M, Wang J, Ding G, et al. Transfer joint matching for unsupervised domain adaptation. Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 1410-1417.
[7] Wang J, Chen Y, Hao S, et al. Balanced distribution adaptation for transfer learning. 2017 IEEE international conference on data mining (ICDM). IEEE, 2017: 1129-1134.
[8] Zhang J, Li W, Ogunbona P. Joint geometrical and statistical alignment for visual domain adaptation. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1859-1867.
[9] Li S, Song S, Huang G, et al. Domain invariant and class discriminative feature learning for visual domain adaptation. IEEE transactions on image processing, 2018, 27(9): 4260-4273.
[10] Wang J, Feng W, Chen Y, et al. Visual domain adaptation with manifold embedded distribution alignment. Proceedings of the 26th ACM international conference on Multimedia. 2018: 402-410.
[11] Luo L, Chen L, Hu S, et al. Discriminative and geometry-aware unsupervised domain adaptation. IEEE transactions on cybernetics, 2020, 50(9): 3914-3927.
[12] Zou Y, Yu Z, Liu X, et al. Confidence regularized self-training. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 5982-5991.
[13] Kang G, Jiang L, Yang Y, et al. Contrastive adaptation network for unsupervised domain adaptation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 4893-4902.
[14] Chen C, Xie W, Huang W, et al. Progressive feature alignment for unsupervised domain adaptation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 627-636.
解读:徐 宁 东南大学
审核:张 琨 合肥工业大学

Frontiers of Computer Science
Frontiers of Computer Science (FCS)是由教育部主管、高等教育出版社和北京航空航天大学共同主办、SpringerNature 公司海外发行的英文学术期刊。本刊于 2007 年创刊,双月刊,全球发行。主要刊登计算机科学领域具有创新性的综述论文、研究论文等。本刊主编为周志华教授,共同主编为熊璋教授。编委会及青年 AE 团队由国内外知名学者及优秀青年学者组成。本刊被 SCI、Ei、DBLP、INSPEC、SCOPUS 和中国科学引文数据库(CSCD)核心库等收录,为 CCF 推荐期刊;两次入选“中国科技期刊国际影响力提升计划”;入选“第4届中国国际化精品科技期刊”;入选“中国科技期刊卓越行动计划项目”。
《前沿》系列英文学术期刊
由教育部主管、高等教育出版社主办的《前沿》(Frontiers)系列英文学术期刊,于2006年正式创刊,以网络版和印刷版向全球发行。系列期刊包括基础科学、生命科学、工程技术和人文社会科学四个主题,是我国覆盖学科最广泛的英文学术期刊群,其中12种被SCI收录,其他也被A&HCI、Ei、MEDLINE或相应学科国际权威检索系统收录,具有一定的国际学术影响力。系列期刊采用在线优先出版方式,保证文章以最快速度发表。
中国学术前沿期刊网
http://journal.hep.com.cn

特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






