|
|
|
|
|
FCS|前沿解读:对用户行为启示在检索模型中作用的理解性研究 |
|
|
论文标题:Understanding the role of human-inspired heuristics for retrieval models(前沿解读:对用户行为启示在检索模型中作用的理解性研究)
期刊:Frontiers of Computer Science
作者:Xiangsheng LI, Yiqun LIU, Jiaxin MAO
发表时间:15 Feb 2022
DOI:10.1007/s11704-020-0016-y
微信链接:点击此处阅读微信文章
原文信息
标 题:
Understanding the role of human-inspired heuristics for retrieval models
发表年份:
2022年
原文链接:
https://journal.hep.com.cn/fcs/EN/10.1007/s11704-020-0016-y
引用格式:
Xiangsheng LI, Yiqun LIU, Jiaxin MAO. Understanding the role of human-inspired heuristics for retrieval models. Front. Comput. Sci., 2022, 16(1): 161305
公众号推文链接:
对用户行为启示在检索模型中作用的理解性研究
01导读
相关性评估是信息检索领域的核心之一。现有的检索模型虽然在建立搜索系统上取得了很大的进展,但由于其工作方式没有考虑到用户的搜索行为模式,所以与人的相关性判断模式仍存在很大差异。因此,系统地研究用户在相关性判断过程中的认知行为,并将这些启发式方法引入检索模型中,具有重要的现实意义。
本文形式化定义了 6 种用户阅读启发式方法:顺序阅读、垂直注意力衰减、以查询为中心引导、上下文感知阅读、选择性注意力、提前停止,并且研究了每种启发式方法在检索模型中对应的建模策略。本文通过实验比较了检索模型中的不同策略对排序性能的提升效果。实验证明,大多数阅读启发式方法都可以有效提升模型性能。对于顺序阅读方法,其将整个文档分为几块细粒度内容,并使用位置嵌入对文本顺序进行建模。对于垂直注意力衰减方法,其将人的注意力作为监督信号,为注意力学习提供归纳偏置。对于以查询为中心引导方法,多级 CNN 和核池化方法可以提供良好的排序性能和计算效率。对于上下文感知阅读方法,其使用顺序模型来根据上下文信息估计局部相关性。对于选择性注意力和提前停止方法,其利用强化学习能有效地提高排序性能。
本文的工作对信息检索模型的改进有一定的启发,为从认知行为的角度构建检索模型提供了思路。
02 主要方法
形式化阅读启发式方法
本文形式化地定义了 6 种直观且有效的阅读启发式方法。
顺序阅读
由于阅读顺序一般是从文档顶部到底部,文档的内容顺序会影响相关性,所以内容相同但顺序不同的文档相关性不同。顺序阅读方法定义如下:
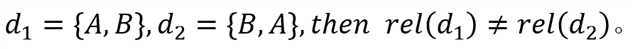
垂直注意力衰减
研究表明,用户在阅读中的注意力呈垂直衰减趋势,说明开头文本有更重要作用,因此应该赋予更大的权重。垂直注意力衰减方法定义如下:
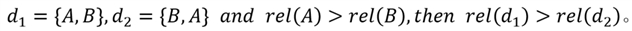
以查询为中心引导
用户的阅读注意力受到搜索目标的影响,而查询词可以直接体现出搜索目标。因此,对查询和文档之间的交互进行建模有助于准确估计相关性。
上下文感知阅读
利用上下文信息构建的检索模型,与不参考上下文信息的检索模型相比,误差值更小。因此结合上下文可以更好地估计相关性。上下文感知阅读方法定义如下:

其中,  表示两者之间的误差,R表示相关性真实值。
表示两者之间的误差,R表示相关性真实值。
选择性注意力
用户通常会选择重要的文本内容进行阅读,而忽略无关部分。所以会存在一个包含部分原文档句子的子文档,使得该文档与原文档的相关性相同。选择性注意力方法定义如下:
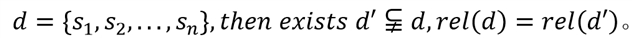
提前停止
当用户大致了解明白文档内容后,可能会在当前阅读位置提前停止阅读。所以存在一个位置 k,使得原文档与包含 k 之前内容的子文档的相关性相同。提前停止方法定义如下:

检索模型的阅读启发式方法建模
信息搜寻过程分为信息关联和知识积累。在相关性评估中,形式化定义用户阅读过程如下式所示:
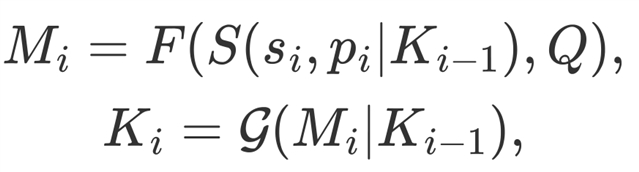 (1)
(1)
其中, 是文档的最小文本单元(如句子、段落), 是
是文档的最小文本单元(如句子、段落), 是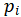 中的一个位置。
中的一个位置。 是达到位置i 时的知识积累,S是控制是否忽略的选择函数。F 是提取语义信息的局部相关估计函数,用于评估和查询Q之间的局部相关性。
是达到位置i 时的知识积累,S是控制是否忽略的选择函数。F 是提取语义信息的局部相关估计函数,用于评估和查询Q之间的局部相关性。 是当前和Q之间的交互语义信息,包含已获得知识和相关性置信度。
是当前和Q之间的交互语义信息,包含已获得知识和相关性置信度。 是积累当前阅读信息的集合函数。
是积累当前阅读信息的集合函数。
本文将用户阅读启发式方法加入信息检索模型,提出了阅读启发式建模框架,如图1所示。
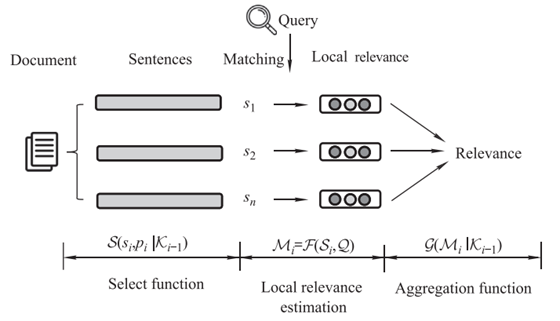
图1.阅读启发式建模框架
顺序阅读()
内容的呈现顺序会影响相关性,所以对每个内容的位置进行建模。本文在特征层增加了位置嵌入,提供了当前位置顺序的显式信息,如下式所示:
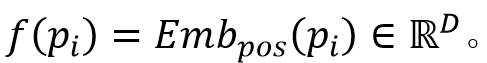 (2)
(2)
为了表示位置的内部顺序和相邻关系,可以采用相对位置嵌入方法,如下式所示:
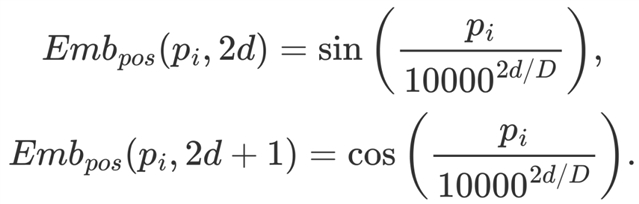 (3)
(3)
与绝对位置嵌入相比,相对位置嵌入随位置的增加而平滑移动,并在嵌入空间内相互关联。
垂直注意力衰减()
用户在阅读时的注意力垂直递减,即注意力主要集中在文档的开头部分,所以要对文档的开头内容增加权重。本文提出两种策略来对垂直注意力衰减进行建模,分别是垂直衰减系数和注意力衰减学习。
垂直注意力衰减是将每个嵌入乘以衰减系数,该系数由用户阅读注意力的总体分布(使用 Gamma 分布拟合)生成,生成方式如下:
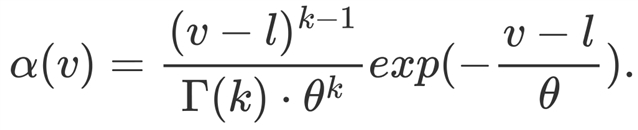 (4)
(4)
集合函数定义为语义信息和衰减系数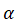 的乘积:
的乘积:
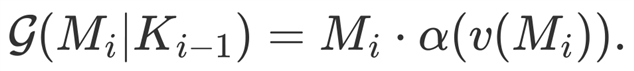 (5)
(5)
注意力衰减学习分为无监督和有监督两类。
无监督注意力衰减学习是通过正则化注意力函数,使其具有相似的衰减分布。集合函数定义如下:
 (6)
(6)
特别地,在垂直方向下降的正则化注意力权重公式如下:
 (7)
(7)
有监督注意力衰减学习是将公式(4)的拟合的 Gamma 分布作为监督信号,最小化每个注意力权重和用户在特定垂直位置的注意力值之间的平方误差,定义方法如下:
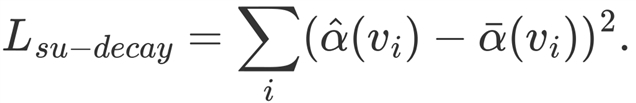 (8)
(8)
在注意力衰减学习中,还可以引入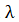 来避免过拟合,并利用排序损失进行优化,即
来避免过拟合,并利用排序损失进行优化,即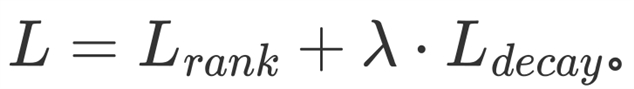 。
。
以查询为中心的引导(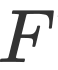 )
)
此方法旨在计算文档内容和查询之间的相关性,包括精确查询匹配和语义查询匹配、邻近性和词重要性。精确查询匹配和语义查询匹配分别根据语义匹配矩阵 和精确匹配矩阵
和精确匹配矩阵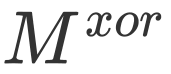 来建模。本文分别提出空间邻近建模和语义邻近建模两种建模策略,定义如下:
来建模。本文分别提出空间邻近建模和语义邻近建模两种建模策略,定义如下:
 (9)
(9)
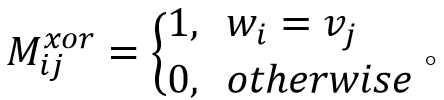 (10)
(10)
空间邻近是指在一固定范围内的联通性。空间邻近建模可以为构建交互表示提供有效的上下文信号。经典方法包括多层卷积神经网络、空间循环神经网络。
语义邻近聚类了不同强度的语义匹配,旨在表示每个局部交互群的层次。经典方法包括匹配直方图映射和核池化。匹配直方图映射是直接将每个颜色分量的局部交互次数作为直方图值。核池化是端到端的建模方法,利用 RBF 核计算词对相似度分布,定义如下:
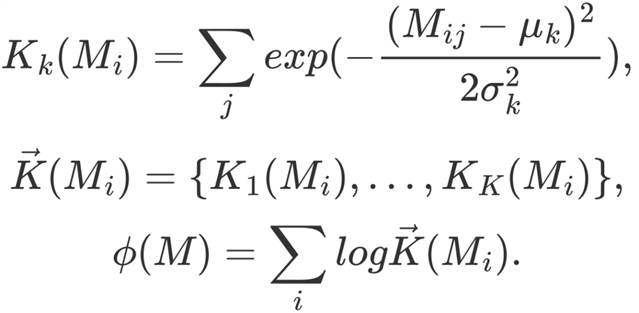 (11)
(11)
上下文感知阅读( )
)
用户的局部相关性感知是基于之前阅读文本不断积累的,需要融合上下文信息进行建模。方法包括句级卷积神经网络和顺序模型。
句级卷积神经网络对文档中连续的由n个句子组成的序列进行建模。利用一维 CNN,对每个滑动窗口使用特征检测器提取包含上下文的语义信息。
顺序模型(如 RNN)可以利用记忆信息对之前输入的所有序列进行处理,能考虑到更大范围的上下文信息。
选择性注意力( )
)
此方法表明在相关性评价时可以跳过一些不相关的文本,而且不会对模型结果造成影响。对公式(1)的选择函数进行建模。具体策略包括以查询为中心的注意力机制和强化学习。
以查询为中心的注意力机制只关注查询周围的上下文信息,忽略其他句子。
强化学习可以用于学习不同句子的重要性,策略函数定义如下:
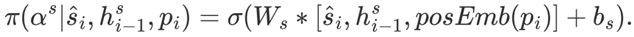 (12)
(12)
使用RNN模型对集合函数进行建模,公式如下:
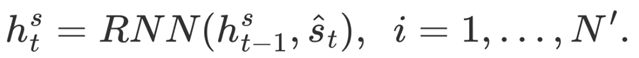 (13)
(13)
奖励定义为相关性预测的表现,指导模型去学习更好的表现效果和采取恰当的动作。本文设计了三类奖励函数,如下所示:
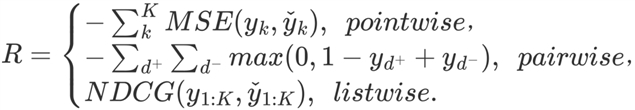 (14)
(14)
采用策略梯度优化来最大化奖励期望,梯度定义如下:
 (15)
(15)
提前停止()
此方法表明当文本足够进行相关性评估时,用户会停止阅读。与选择性注意力相似,此方法也是对选择函数进行建模。具体策略包括固定部分数据建模和动态停止两种。
固定部分数据建模是根据文档的前百分比内容来估计相关性,例如保留文档内容的 20%、40%、60%、80%。
动态停止利用强化学习,让agent来决定收集到的信息是否足够停止阅读。使用多层感知机来确定不同动作的概率,提前停止的策略函数定义如下:
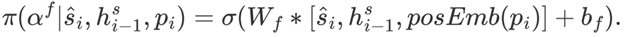 (16)
(16)
奖励函数见公式(14)。
选择性注意力(公式14)和提前停止(公式16)可以在检索模型中一起学习。为了简化流程,本文提出如下算法将两个启发式方法融合。

03 主要贡献
根据用户的搜索阅读行为,提出了 6 种阅读启发式方法:顺序阅读、垂直注意力衰减、以查询为中心引导、上下文感知阅读、选择性注意力、提前停止。
对于每种启发式方法都使用公式进行形式化定义,并提出具体的方法策略。
将启发式方法融入到信息检索模型中,通过实验对比各方法的不同策略对模型排序性能的影响,并给出结果分析和改进建议。
04 实验
实验设置
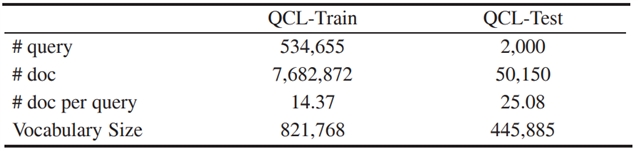
本文使用大规模公开数据集QCL,通过实验来验证不同阅读启发式方法的有效性。QCL数据集来自搜索引擎搜狗的真实搜索日志,数据集情况如表 1 所示。数据集包含弱相关标记,即来自 5 个不同点击模型的点击相关标记。据以前的研究表明,来自点击模型的弱相关标记可以比普通点击信号更好地用于模型的训练和评估。
表1.QCL数据集统计
使用 AdaDelta 算法优化参数。使用 word2vec 训练词嵌入,设置维度为 50,隐藏向量维度设置为 128,位置嵌入维度设置为 3。CNN 的过滤器窗口大小设置为 2-5s,每个过滤器有 64 个特征图。使用 GRU 作为顺序模型。在无监督注意力衰减模型中,设置边界距离 为 0.01。在选择性注意力和提前停止的强化学习中,训练选择 pointwise 奖励,每个文档的采样动作序列数为 5,探索率为 0.2。
实验结果
NDCG(Normalized Discounted Cumulative Gain)是归一化折损累计增益,用于评估模型计算出的排序结果。
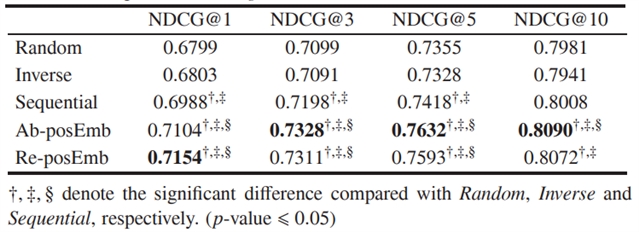
由表 2 可知,顺序要优于随机顺序和倒序,同时位置嵌入能提升排序性能,但绝对位置嵌入和相对位置嵌入的差异不显著。
表2.不同策略的顺序阅读的排序性能
由表 3 可知,衰减系数无法提高排序性能,所以不适合加入模型。在正则化衰减的注意力机制中,无监督方式只会降低性能,而将人的注意力作为监督信号时,可以明显地提升性能。
表3.不同策略的垂直注意力衰减的排序性能

由表 4 可知,核池化策略要明显优于其他策略,说明端到端的软匹配可以为检索模型提供更多重要语义信号。在空间邻近中,多级 CNN 优于空间 RNN,说明多级 CNN 更适合检索模型。在语义邻近中,匹配直方图效果不佳,说明简单计算局部交互不能很好捕获语义匹配。
表4.不同策略的以查询为中心引导的排序性能

由表 5 可知,上下文感知建模(RNN、1-D CNN)要优于上下文无关建模(MLP)。其中,RNN 的指标高于 1-D CNN,说明 RNN 能更好地对上下文信息进行建模。
表5.不同策略的上下文感知阅读的排序性能
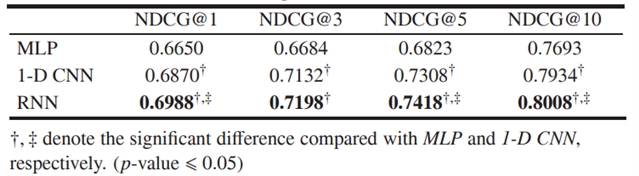
由表 6 可知,强化学习策略要优于以查询为中心的策略,说明动态选择注意力可以帮助检索模型有选择地捕获重要信息,获得更好的排序性能。
表6.不同策略的选择性注意力的排序性能
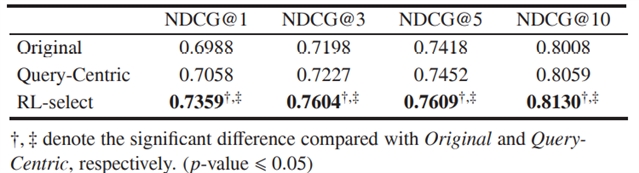
由图 2 可见,使用强化学习的动态停止策略的效果要优于在固定位置停止的策略。随着数据百分比的增加,排名性能会越来越高。80%数据与全部数据具有相似的排名性能,意味着检索模型可以通过减少文档中不必要的内容来提高计算效率。
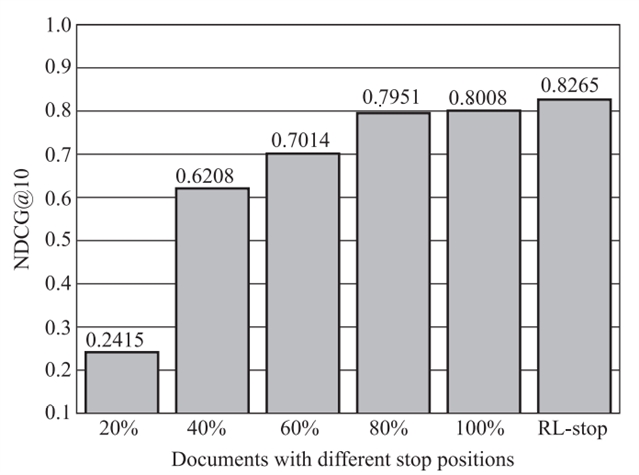
图2.不同停止位置的排序性能
摘要
Relevance estimation is one of the core concerns of information retrieval (IR) studies. Although existing retrieval models gained much success in both deepening our understanding of information seeking behavior and building effective retrieval systems, we have to admit that the models work in a rather different manner from how humans make relevance judgments. Users’ information seeking behaviors involve complex cognitive processes, however, the majority of these behavior patterns are not considered in existing retrieval models. To bridge the gap between practical user behavior and retrieval model, it is essential to systematically investigate user cognitive behavior during relevance judgement and incorporate these heuristics into retrieval models. In this paper, we aim to formally define a set of basic user reading heuristics during relevance judgement and investigate their corresponding modeling strategies in retrieval models. Further experiments are conducted to evaluate the effectiveness of different reading heuristics for improving ranking performance. Based on a large-scale Web search dataset, we find that most reading heuristics can improve the performance of retrieval model and establish guidelines for improving the design of retrieval models with humaninspired heuristics. Our study sheds light on building retrieval model from the perspective of cognitive behavior.
解读:徐 宁 东南大学
审核:张 琨 合肥工业大学

Frontiers of Computer Science
Frontiers of Computer Science (FCS)是由教育部主管、高等教育出版社和北京航空航天大学共同主办、SpringerNature 公司海外发行的英文学术期刊。本刊于 2007 年创刊,双月刊,全球发行。主要刊登计算机科学领域具有创新性的综述论文、研究论文等。本刊主编为周志华教授,共同主编为熊璋教授。编委会及青年 AE 团队由国内外知名学者及优秀青年学者组成。本刊被 SCI、Ei、DBLP、INSPEC、SCOPUS 和中国科学引文数据库(CSCD)核心库等收录,为 CCF 推荐期刊;两次入选“中国科技期刊国际影响力提升计划”;入选“第4届中国国际化精品科技期刊”;入选“中国科技期刊卓越行动计划项目”。
《前沿》系列英文学术期刊
由教育部主管、高等教育出版社主办的《前沿》(Frontiers)系列英文学术期刊,于2006年正式创刊,以网络版和印刷版向全球发行。系列期刊包括基础科学、生命科学、工程技术和人文社会科学四个主题,是我国覆盖学科最广泛的英文学术期刊群,其中13种被SCI收录,其他也被A&HCI、Ei、MEDLINE或相应学科国际权威检索系统收录,具有一定的国际学术影响力。系列期刊采用在线优先出版方式,保证文章以最快速度发表。
中国学术前沿期刊网
http://journal.hep.com.cn

特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






