复旦大学计算机科学技术学院教授颜波团队提出了一种实现数据高利用率的基础模型训练框架,利用可控生成式人工智能(AI)生成合成数据,并采用“真实数据+合成数据”的混合数据模式训练基础模型,为解决数据稀缺难题提供了新思路。相关研究近日发表于《自然-生物医学工程》。
基础模型是一种基于深度神经网络和自监督学习(SSL)技术,在大规模、广泛来源数据集上训练的AI模型。相较于只能完成特定任务的专用AI模型,基础模型的独特之处在于其强大的泛化能力。然而,大规模高质量数据的获取成本高昂、耗时漫长,还具有隐私泄露风险。在一些数据稀缺场景,传统基础模型训练方法效果受限,难以推广。
研究团队将目光瞄准了AI合成数据,采用大量合成数据让模型学习,弥补现有真实数据的不足。团队在少量公开的真实医学数据上微调可控生成式AI,整合特定疾病知识,并以疾病概念作为条件生成大规模合成医学数据集。医学基础模型先后在合成数据和有限真实数据上使用SSL技术预训练,以初始化模型参数并学习精确医学表征。最后,团队通过带明确标签的监督微调基础模型,使其适配特定任务。
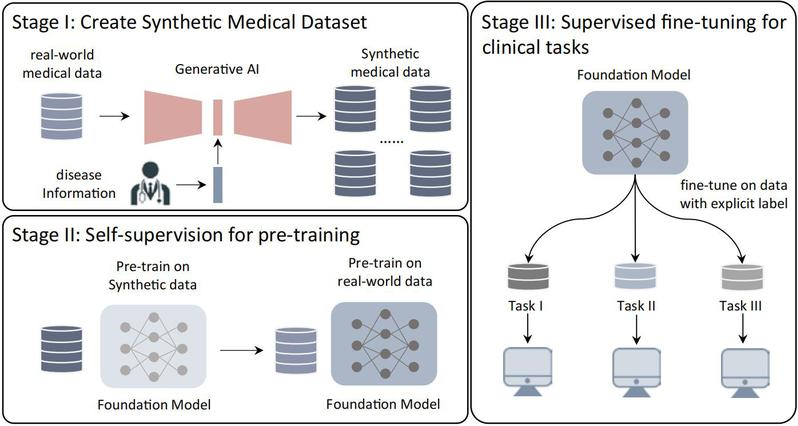 数据高效的医学基础模型训练框架。图片由研究团队提供
数据高效的医学基础模型训练框架。图片由研究团队提供
为了确保合成数据在模型训练中的有效性,团队一方面基于真实数据标签生成合成数据,与真实数据特征非常接近;另一方面,在训练过程中引入条件混合增强,使数据特征更加多样。团队遵循该方法构建的首个基于合成数据的视网膜基础模型,以及胸片X光基础模型都展现了较好的性能和泛化能力,进一步验证了该训练框架的有效性。除了智慧医疗之外,该创新基础模型训练方法目前已经在多个产业实际痛难点中得到初步应用。
该研究还对推动合成数据的应用提供了启发。团队验证了合成数据在泛化能力、标注效率和训练效率上的价值,并详细探索了合成数据在均衡样本分布、合成数据量控制、克服数据偏差等方面的使用方式。
相关论文信息:https://doi.org/10.1038/s41551-025-01365-0
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。






