|
|
|
|
|
中科院心理所研究揭示言语理解中存在对语音信息的预测 |
|
|
哲学家克拉克提出,“大脑在本质上是一个预测机器”。根据当前情境和言语信息,对将要出现的信息进行预测是人类重要的认知智能。在日常交流中,我们常常遇到一方话音未落,另一方已经猜到对方想要表达什么的情况。无论是日常生活经验抑或实验证据,均表明人们能够对言语信息进行预测。当前,关于言语预测的一个关键研究问题是语言预测内容,即人们能够预测哪些层级的语言信息。目前研究揭示,言语理解中存在对句法、语义信息的预测。但是,关于语音特征能否被预测研究较少且争议较大。
为了考察人们在言语理解中能否预测语音信息,中国科学院行为科学重点实验室李兴珊研究组的青年特聘研究员屈青青及同事在一项最新研究中采用视觉情境眼动范式,以汉语作为研究材料,开展了两项实验研究。汉语可以更好地分离语音与字形信息,以考察更纯净的语音预测效应。
实验一考察了汉语言语理解中的语义和语音预测。实验中,被试听到含有高预测性目标词的句子,例如“要放学了,我把铅笔盒和本子装进了书包里准备回家。”在预测目标词出现前2秒,屏幕呈现图片刺激,图片刺激包括一个关键物和三个干扰物。关键物包含以下条件:目标物(如“书包”)、语义相关项(如“橡皮”)、语音相关项(如“梳子”),以及作为基线条件的无关物(如“漏斗”)。在此过程中记录被试的眼动轨迹。实验预期,如果在预测目标词呈现前,被试已经更多注视屏幕中的语义相关项、语音相关项,表明被试预先激活了目标词的语义和语音信息。
研究结果发现,与无关物相比,被试更多地注视语义相关项、语音相关项。更重要的是,这种注视偏好开始于被试听到目标词之前(见图1)。结果表明,被试在目标词呈现之前预先激活了目标词的语义、语音信息。实验二采用新的实验材料以及更短的预视时长(1秒)开展了重复性验证实验,结果重复了实验一的语音预测效应。
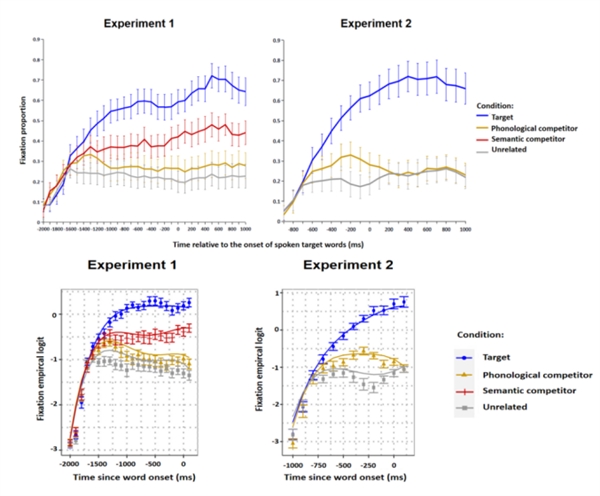
上图:实验一、实验二实验条件下注视比例图。蓝色线表示目标物条件,黄色线表示语音相关项条件,红色线表示语义相关项条件,灰色线表示无关物条件,横轴表示预测目标词呈现时间(时间0代表预测目标词开始呈现),纵轴表示注视比例,误差线表示标准误;下图:实验一、实验二预测时间窗口内实验条件生长曲线分析图。横轴表示预测目标词呈现时间,纵轴表示经验逻辑转换后注释比例,曲线表示模型拟合情况
综上所述,该研究考察了言语理解中的预测内容,揭示了言语理解中对下文语义与语音信息的预测,该成果有助于加深对预测内容与加工机制的理解,将为构建更完整的语言理解模型提供科学证据,为自然语言处理和语言类脑智能提供重要启示。
该研究受国家自然科学基金面上项目(31771212)、中国科学院青年创新促进会人才项目、中国科协青年人才托举项目、国际(地区)合作与交流项目(62061136001)的资助。
该研究成果已在线发表于Journal of Experimental Psychology: Human Perception and Performance,文章的第一作者为硕士生李欣晶,通讯作者为心理所青年特聘研究员屈青青。
相关论文信息:
Li, X., Li, X., & Qu, Q.* (2022). Predicting phonology in language comprehension: Evidence from the visual world eye-tracking task in Mandarin Chinese. Journal of Experimental Psychology: Human Perception and Performance, 48(5), 531–547. https://doi.org/10.1037/xhp0000999
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






