|
|
|
|
|
你了解数据期刊么?你知道什么是“人类企鹅项目”么?| Scientific Data投稿经历分享 |
|
|
论文标题:Data from the Human Penguin Project, a cross-national dataset testing social thermoregulation principles
期刊:Scientific Data
作者:Chuan-Peng Hu et al.
发表日期:2019/04/17
数字识别码:doi:s41597-019-0029-2
原文链接:https://go.nature.com/2JppTHS

本文转载自:OpenScience
最近,由12个国家15个心理学研究者团队合作收集、由本人与殷继兴(西北师范大学心理学院)主要负责整理的数据——人类企鹅项目数据——发表在数据期刊 Scientific data上(Hu et al., 2019)。这对于一直在推Open Science的我来说,是非常值得开心的,因为这说明科学界也奖励分享研究数据本身。也就是说,研究者用于整理数据的投入是有价值的。所以个人感觉这个经历也值得与大家分享。
01 项目介绍
人类企鹅项目(Human Penguin Project, HPP)由荷兰研究学研究者Hans IJzermanrn所发起的一项多中心合作项目。这个项目的主要目的是验证社会关系是否能够帮助人们进行体温调节。这个问题看起来像是温度的具身认知(如“摸热杯子让人更友好”的效应),在众多具身认知实验无法被成功重复的背景下,社会关系与体温调节的相关性听起来也可能不太可靠。但是,社会关系与体温调节之间的关系不仅仅是“启动”那么简单,而是可能存在真实的生物进化上的基础,有兴趣可以阅读(IJzerman et al., 2018)。
与其他多中心合作项目一样(孔祥祯, 2019),HPP在多个国家(N=12)收集社会关系数据(自我报告)和体温数据(使用口腔温度计)。当然,除了这两个最主要的变量外,我们还收集了许多其他的数据。我们公开了这个项目中绝大部分主要数据(primary data),即清理后的原始数据。
与其他公开数据集仅公开数据不同,我们在公开数据时,也整理并公开了9种语言的问卷。实际上,将不同语言的问卷与数据一起公开,是我们公开数据的最初动力:这样可以避免研究者重复地翻译一些常用的问卷。
具体而言,我们的数据包括下表中所涉及到的变量:
|
变量
|
内容
|
|
体温
|
口腔温度 (两次测量)
|
|
生理相关信息
|
是否用药(如果是,何种药物)*
是否抽烟 (如果是,一天抽多少支)
每天的含糖饮料 (数据中的“gluctot”)
不含糖饮料 (数据中的“artgluctot”)(Henriksen, Torsheim, & Thuen, 2014)
|
|
基本信息
|
生日、性别、身高*、体重*、性取向*、
是否处于恋爱关系、一夫一妻制的态度、
自我报告的健康状况、语言
|
|
地点与气候
|
当天的最低温度、当天的平均温度、
当地与赤道的距离、纬度*
|
|
社会关系网络
|
社会网络指标32 个条目(Cohen, Doyle, Skoner, Rabin, & Jack M. Gwaltney, 1997): 网络大小, 网络嵌套, 复杂关系 (CSI)
|
|
相对成熟的问卷
|
特质自我控制(Tangney, Baumeister, & Boone, 2004) (13 项目)、
知觉到的压力(Cohen, Kamarck, & Mermelstein, 1983) (14 条目) 、
怀旧量表(Barrett et al., 2010; Zhou, Wildschut, Sedikides, Chen, & Vingerhoets, 2012)、
对家的依恋 (Harris, Brown, & Werner, 1996)、
手机和网络依赖(Yildirim & Correia, 2015)、
亲密关系体验问卷修订版(Fraley, Waller, & Brennan, 2000) (包括焦虑和回避两个子量表)、
多伦多述情障碍量表 (TAS-20)(Kooiman, Spinhoven, & Trijsburg, 2002)
|
|
新量表
|
社会体温调节与风险回避问卷 (STRAQ-1)(Vergara et al., 2018) #、感动频率问卷 (KAMF) (Zickfeld et al., 2019)
|
* 为避免被试的隐私,这些变量未包括在公开数据之中,如您需要这些数据,可以联系我(hcp4715@gmail.com)或者合作者Hans(h.ijzerman@gmail.com)
# 见 Vergara et al. (2018) for the final version of STRAQ-1.
02 数据收集与清理
本人参与这个项目是比较巧合的,有个师弟正好认识Hans,知道他在满世界找合作者(2015年左右),缺中国的合作者;又正好,这位师弟知道我对Open Science非常感兴趣,于是他询问我的意向。我当时正对Open Science一腔热血无处抛洒,于是痛快地答应。随后我与Hans取得联系并开始准备材料,当时的主要工作是对英文材料进行本土化。对于那些已经翻译并且验证过的问卷(少量的),我们直接采用;对于没有翻译的问卷,我们进行了翻译-回译。2016年上半年开始收集数据。当时我去英国交换,无法直接收集数据。特别感谢几位本科生同学在做他们项目的时候,帮我收集完了数据:湖北大学的杨宇翔、刘媛媛、简晶莹和刘青兰。
数据收集后,在清理数据的过程中,与Hans进行了几次核对。最终,Hans完成了对主要结果的分析:使用随机森林的方法,以体温作为被预测变量,其他测量的变量作为预测变量。数据显示,社会关系中的一个指标对于预测体验来说确实还挺重要的:Complex Social Integration。这个指标指的实际上是关系的多样性,按照关系的类型进行计算,数字越大代表关系越多样。但是这个文章投稿不顺利,从2016年一直被拒到2018,最后终于发表在了一个新的杂志Collabra. Psychol.上。
在整个论文数据收集、整理和论文写作、投稿中,我都是酱油,也没有太投入时间。但是,我正在进行的一个合作项目是对Belief in Free Will的一个量表进行修订。突然有一天我想到,在HPP里面包含了许多问卷的多语言版本,如果我们就让它们无声无息地放在OSF上,有多少人知道它们的价值与意义呢?于是我跟Hans说,我们可以把原始数据与问卷整理一下,作为一个数据描述文章投出去,至少比较正式地介绍我们的数据。这大约是2018年年初(或者是2017年年底)。
然后,我们(主要是我)就开始重新整理数据,并根据数据进行整理编码手册(codebook),方便其他数据使用者能够清晰地知道我们的数据中有哪些变量。很快我发现精力实在不够,于是我叫上了殷继兴帮助。我们花了不少时间,根据SPSS数据、问卷以及Hans之前清理数据的记录,终于把数据和codebook厘清了。我们也把9种语言的施测材料找过来,按照问卷的结构将所有问卷整全到一个Excel表格之中,方便同行进行对照查阅。在这个过程中,继兴经历了再次考研到最终西北师大。终于在Hans的主要文章正式发表后不久,我们的数据文章也可以投稿了。
Tips:在问卷数据及类似数据整理的过程中,我们采用的方式是.csv文件数据+excel文件的codebook,即对于每个数据,均有一个数据文件和一个codebook文件。在数据文件中(UTF-8编码或者Unicode编码的csv文件),基本按照SPSS数据格式,即第一行是列名(与R里colnames对应)变量或者数据名,其余每行代表一个被试的数据,比如我们数据中一个截图:
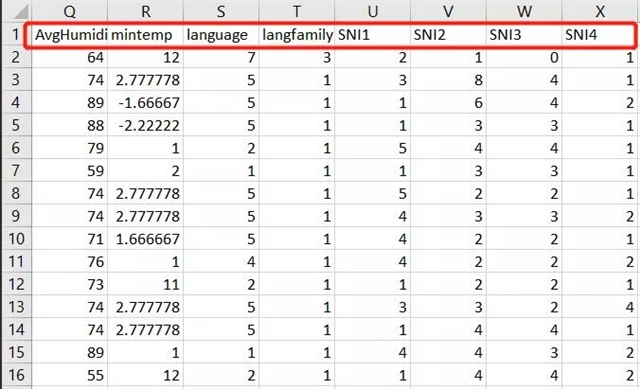
而Codebook中,必须有一列与数据文件中的这些列名对应:
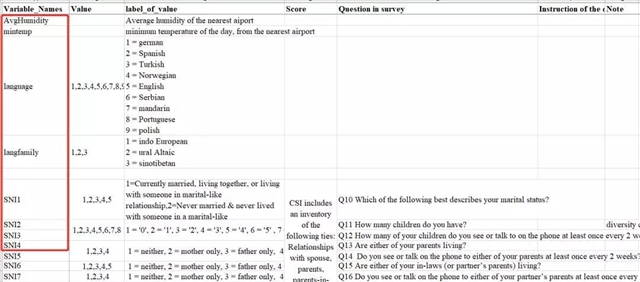
当然,这种数据文件+codebook的方式,不太适合机读,可能不太适合更大规模的数据。目前一些研究者正在试图整合标准化的心理学数据格式(https://github.com/psych-ds/psych-DS),期待能够有更简单快捷且能够机读的数据组织形式的出现!
数据整理好之后,需要选择投稿的期刊。目前,数据描述类文章可选的杂志不多,我所了解到的包括GigaScience,Scientific Data,Journal of Open Psychological Data,Data in Brief 等。Frontiers系列里也有数据描述这种文章类型,我们之前关于P值理解的调查以这种形式发表了(见doi.org/10.3389/fpsyg.2018.00868)。GigaScience主要是生物学大数据的,似乎没有心理学相关的数据,所以我们没有考虑。接下来就是Sci. Data,这个杂志是Nature Research旗下的期刊,创刊不久。我们想试一下Sci. Data,但没有抱太大的希望,因为Sci. Data影响因子不低,而且我所了解的数据文章都是费了很大成本才收集到的,比如左西年老师(Zuo et al., 2014)的Consortium for Reliability and Reproducibility(CoRR)和西南大学刘威同学作为一作的Longitudinaltest-retest neuroimaging data (Liu et al., 2017),都是MRI数据。而我们的数据收集的成本相对比较低。
但不管怎么样,试一下再说,于是我们投到了Sci. Data。碰到的第一个问题是版权协议。由于欧盟的新数据保护规则,杂志对于从人类被试采集的数据很谨慎的,避免隐私的麻烦。对于我们的数据来说,一方面,我们数据中能够识别出个人身份的信息不多,可能主要就是IP的数据,但这个我们早已经去掉了。但同时,我们的知情同意书中写明了我们会以多个被试集体数据的形式发表在科研论文中。欧盟的数据保护规则中,明确要求是,对于任何目的都必须要当事人明确地许可,也就是说,该保护规则生效之后,未经明确许可即禁止。但该规则是2018年生效的,我们的数据是2016年采集的,理论上讲不适用的。总共进行了好几个邮件来回后,我们在cover letter里加了一段说明,解释为什么我们可以使用CC-BY 4.0作为我们数据的协议,能够尽可能地保护被试的隐私(上面的表格中有注释,对于有些可能能够识别出被试身份的,我们需要特别申请才能使用,具体而言,我们需要数据使用者有IRB的批准,认为他们不会公开我们的数据)。终于,Sci. Data接受了我们的投稿,进行了下一个环节:审稿。
Tips:如果你最近在收集数据并且想以后公开数据,最好要考虑在知情同意书里明确加上需要被试同意公开分享数据,尤其是要提到公开后的数据是无法撤回或者修改的,因为欧盟的新数据保护规则是一旦个体要求自己的数据被删除,数据收集者应该删除数据。可以参考OpenScience公众号之前组织翻译的Open Brain Consent.
非常幸运的是,审稿人对我们数据的态度还是比较积极的,觉得我们的数据对于社会人格心理学有意义,且数据组织很清晰易懂,方便重复使用。但让我们对前言背景进行再次补充,并且加强关于数据再利用的价值部分,告诉同行我们的数据可能会有什么用途。于是我们增加了许多文字(在psyarxiv上可以看到我们不同版本之间的区别:https://psyarxiv.com/cs6au/)。
修改之后再次提交时,又碰到格式方面的问题:审稿系统中,initial quality check打回来了两次,才再次提交成功。审稿人对我们的修改比较清单,没意见了,负责我们文章的编辑也觉得可以接受,但又提了一些格式的要求,再次提交时,又进行了两次才成功。总之,投稿到后面,主要变成了格式的问题,感觉Nature Research的editorial团队在这方面的容忍度似乎非常低,我后来每次看到他们的邮件都很紧张,因为他们的邮件意味着又要花时间做一些繁琐的事情。
在文章上线之前,还有两件事情。第一、Sci. Data是要交钱的,因为它是一个open access的杂志,所以文章处理费要作者出。与其他的开放获取的杂志相比,它的价格还是可以接收的(2019年的价格:1390欧元,https://www.nature.com/sdata/about/oa)。第二、Sci. Data有自己的元数据格式(meta-data),以保持在他们杂志上的数据文章本身是可以机读的,能够方便被检索到。所以这又意味着需要对这些meta-data进行处理。这方面其实大部分作者都不会有经验,因为主要是信息管理方面的专业知识。当然,他们编辑团队的人会进行邮件告诉你如何做,所以就是琐碎的事情。最近他们正在开发一些工作,让作者能够自己给自己的文章生成元数据,估计以后会方便一些。
03 投稿感悟
最后,想说的是,能够有一个数据文章出来也是蛮开心的。自己近几年都在试图使用Open Science的方式做研究,知道做Open Science在现阶段很不容易,因为很多工作还是没有回报的(也就是出力不讨好)。如果没有Sci. Data或者其他接受数据文章的杂志,也许我们花的很多时间来整理数据和问卷,最后都没有什么回报,而许多同行也可能不知道我们有这样的一批数据公开了(目前已经有两位研究者申请使用那些我们未公开的敏感数据了)。所以我蛮感谢有这样杂志的存在,让清理数据这样有价值的工作得到了应有的奖励。当然,我们的数据的价值有多大,最终需要由同行来评估,而不是由Sci. Data决定。所以我也希望有更多地同行去利用这些原始数据去探索和验证一些假设,这样可能能够节省一些钱、一些研究的时间。
最后的最后,既然都看到这里了,我也说一下我们的数据有哪些潜在的用途:(1)验证一些量表的跨文化测量的不变性或者说是等同性,这个问题是最近心理测量中比较重要的一问题;(2)文化和语言是否调节社会关系与体温之间的关系?在Hans 2018的文章中,我们发现语系(language family)也是预测体验的一个非常重要的因素,但目前我们没有系统地探索过这个问题,结合一起公开的数据,比如文化的松紧、权力距离等,是否能够进一步探索文化和语言对社会关系与体温之间的关系,是否在东方文化下,社会关系对体测的影响更加重要?(3)一些我们研究未作为关键的变量:主观压力、亲密关系、怀旧、健康等(数据、问卷和代码都可以通过链接:osf.io/h52d3/ 获取)。同时,如果想使用随机森林的方法来探索这批数据(其分析代码也可以通过链接:osf.io/6yu5d/ 获取)。
注:本文已获原作者授权转载,如需转载,请联系原作者授权。

阅读论文全文,请访问:https://go.nature.com/2JppTHS
期刊介绍:Scientific Data is a peer-reviewed, open-access journal for descriptions of scientifically valuable datasets, and research that advances the sharing and reuse of scientific data. We aim to promote wider data sharing and reuse, and to credit those that share.
(来源:科学网)
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






